
Transkribus Lite
Beschreibung
Transkribus Lite ist eine Plattform primär für die KI-gestützte Layout- und Texterkennung von gedruckten oder handgeschriebenen Dokumenten, ermöglicht aber auch - mit Grenzen - die Annotation von Struktur und Inhalt. Die Plattform geht auf das 2016 ins Leben gerufene READ-Projekt zurück und wird von der 2019 gegründeten Europäischen Genossenschaft READ-COOP SCE zur Verfügung gestellt und beständig weiterentwickelt. Die Genossenschaft hat mittlerweile mehr als 130 Mitglieder (Institutionen und Privatpersonen) in 30 Ländern (Stand April 2023).
Anwendungsbereiche
- automatische KI-gestützte Layout- und Texterkennung von gedruckten und handschriftlichen Texten (OCR bzw. HTR)
- Training eigener Layout- und Texterkennungsmodelle oder Verwendung öffentlicher Modelle
- Anreicherung (Markieren, Taggen, Annotieren) von Struktur und Inhalt von Texten
- Suche in Dokumenten
- Export der Dokumente in verschiedenen Formaten (z. B. TEI-XML)
Transkribus-Ökosystem:
- Digitalisierung (scantent): Mittels LED beleuchtetes, tragbares Scanzelt zum Digitalisieren von Dokumenten z. B. in Archiven und Bibliotheken über Smartphones und App-Unterstützung (DocScan-App)
- Bearbeitung/Transkription und Datenerfassung und Annotation und KI-Training (Transkribus lite & eXpert, citizen&science)
- KI-gestützte Texterkennung (Transkribus lite & eXpert, metagrapho<api>, Transkribus.ai)
- Publikation (read&search): Mittels read&search können die Dokumente aus den Transkribus-Sammlungen öffentlich zugänglich gemacht werden.
Funktionsübersicht
- Automatische Transkription handgeschriebener oder gedruckter Dokumente mittels öffentlicher oder selbst trainierter Modelle
- Separat oder gemeinsam mit Texterkennung ausführbare Layouterkennung
- Training von KI-Modellen zur Layout- und Texterkennung
- Editor mit Bild-Text-Synopse zur
- Korrektur von automatisch erkanntem Text oder manuellen Transkriptionen
- Anreicherung der Dokumentstruktur und des Inhalts (Markieren, Taggen, Annotieren):
- Struktur: Auf dem Faksimile können Regionen ausgezeichnet und diesen ein Strukturtyp (z. B. “paragraph”) zugewiesen werden
- Text: Auszeichnung des Textformats (fett, kursiv, hochgestellt usw.) und Tagging von Textpassagen (z. B. “date”)
- Es lassen sich allerdings nur einfache und keine komplexen Strukturen annotieren (z. B. überschneidende, zeilen- oder seitenübergreifende Annotationen)
- Selbst definierbare Struktur- und Texttags mit optionalen Attributen
- Kollaborative Zusammenarbeit: Nutzer:innen können mit verschiedenen Rollen (“owner”, “editor” und “transcriber”) zu Sammlungen hinzugefügt werden und gemeinsam an Projekten arbeiten.
- Durchsuchen von Tags und Text
- Volltextsuche: Suchbegriffe sind u. a. durch Wildcards modifizierbar
- Fuzzy Search: Findet Ergebnisse, die sich in ein bis zwei Buchstaben vom Suchbegriff unterscheiden
- Smart Search: Bei der Smart Search werden nicht nur die automatisch erkannten Wörter gespeichert, sondern auch mögliche Varianten, was bedeutet, dass auch vom Texterkennungsmodell falsch transkribierte Wörter gefunden werden können. Damit diese Art von Suche möglich ist, muss sie vor dem Durchführen der Texterkennung ausgewählt werden. Sie ist mit 50 % höheren Kosten für die Texterkennung verbunden, da sie speicher- und rechenintensiver ist
- Export der Dokumente in verschiedenen Formaten: TEI XML, PAGE XML, ALTO XML, PDF (Bild- und Transkriptionslayer), Docx, Tags XLSX, Table XLSX
Derzeitige Versionen
- Transkribus eXpert (Standalone-Version, Java-basiert)
- Transkribus Lite (Webversion)
Aufgrund der großen Akzeptanz der Webversion wird nur mehr diese weiterentwickelt, Transkribus eXpert steht zwar weiterhin zur Verfügung, allerdings werden keine neuen Features mehr hinzugefügt. Alle Dokumente, die in Transkribus Lite hochgeladen werden, stehen aufgrund der Speicherung auf den Servern der READ COOP SCE auch in Transkribus eXpert zur Verfügung. Transkribus Lite wird laufend um neue Funktionalitäten erweitert und ist zur Zeit (Stand: Juni 2023) noch nicht so mächtig wie die Standalone-Version.
Tool-Kompatibilität
| IIIF | FromThePage | FairCopy | ediarum | OpenRefine | ba[sic?] | teiPublisher | ediarum.WEB | |
| Transkribus Lite | ❌ | ✅ | 🦄 | 🦄 | ❌ | ❌ | ❌ | ❌ |
Kostenübersicht
- Kostenlos: Erstellen von Sammlungen, Upload von Dokumenten, Layouterkennung, Training von Modellen zur Layout- und Texterkennung, manuelle Transkription,
- Nur automatische Texterkennung mit Kosten verbunden
- Creditsystem (Stand Juni 2023):
- 1 Credit transkribiert 1 handgeschriebene oder 6 gedruckte Seiten
- Credits können on-demand (Minimum 120 Credits für € 18,00) oder im Abonnementsystem (Minimum 300 Credits für € 19,90/Monat) bezogen werden
- 500 Credits bei Registrierung kostenlos
Möglichkeiten und Grenzen
Stärken
- Kein Software-Download oder Installation nötig - nur ein Webbrowser wird benötigt
- Keine Hardwareanforderungen, da Text- und Layouterkennung sowie das Trainieren von Modellen auf den Servern der READ COOP SCE in Innsbruck (Österreich) durchgeführt wird
- Da die Daten auf europäischen Servern gespeichert werden, ist gesichert, dass die Bestimmungen der DSGVO eingehalten werden
- Mehrsprachige Benutzeroberfläche (de, en, es, et, fi, fr, it, nl, pl, pt, sl, sv)
- Gute Anpassung der Layout- und Texterkennung an die jeweilige Dokumentenstruktur und Hand bzw. Hände über das Training eigener Modelle gegeben
- Für kollaborative Arbeit an Transkriptionen mit anderen Transkribus-Nutzer:innen geeignet
- Eigene Struktur- und Texttags definierbar, sodass Konformität mit den TEI-Guidelines erreicht werden kann
- Einbindung von Normdaten möglich (Wikidata ID)
- Schreibrichtung rechts-links wird unterstützt
- Smart Search (höherer Creditverbrauch): Es werden nicht nur ein erkanntes Wort, sondern auch Alternativen gespeichert, sodass nach gut nach (falsch) erkannten Wörtern gesucht werden kann
- Nur Creditverbrauch bei Texterkennung, alle anderen Funktionalitäten (siehe “Kostenübersicht”) sind kostenfrei
- 10 % Discount beim Kauf von Credits als READ-COOP-SCE-Mitglied
- Erhalt von kostenfreien Credits für Studierende und Lehrende durch das Transkribus-Scholarship-Programm möglich, Möglichkeit des Erhalts eines CLARIAH-Stipendiums für Jungforscher:innen
- Teilen von Seiten mit Personen möglich, die nicht registriert sind
Herausforderungen & Probleme
- Transkribus Lite ist (derzeit noch) nicht so mächtig wie das auslaufende, aber immer noch nutzbare Transkribus eXpert
- Um ein eigenes Texterkennungsmodell zu trainieren, werden zwischen 25-75 transkribierte Seiten (5.000-15.000 Wörter) als Trainingsdaten (“Ground Truth”) benötigt, in denen sehr unterschiedliche Fälle vorkommen sollten. 5.000 werden für gedruckte Texte benötigt, bei handgeschriebenen sollten es mindestens 10.000 für jede vorkommende Hand sein. Generell gilt: Je mehr transkribierte Seiten, desto besser die Ergebnisse
- Training von HTR-Modellen kann zeitintensiv sein und bei sehr heterogenen Handschriften eine hohe Fehlerrate aufweisen
- Es können zwar (einfache) Annotationen vorgenommen werden und eigene Tags erstellt werden, allerdings ist der Editor kein vollwertiger Ersatz für ein eigenständiges Annotationstool
- Kein internes Kommunikationstool, um sich mit anderen, gemeinsam an einer Sammlung arbeitenden Nutzer:innen koordinieren zu können (keine Kommentarfunktion, kein Ort, an dem Guidelines für die Transkription abgelegt werden können, usw.)
- Texterkennung mit kostenfreien Credits hat geringere Priorität als mit gekauften
Voraussetzungen
Jedes Tool kann einerseits bestimmte Vorkenntnisse der Benutzer:innen voraussetzen und andererseits auch hinsichtlich der Software-Umgebung gewisse Anforderungen stellen.
Erforderliche Kenntnisse
- EDV-Grundkenntnisse
- Bedienung eines Webbrowsers
Technische Voraussetzungen (Software)
- Stabile Internetverbindung
- Webbrowser
Einrichtung & Erste Schritte (Beispielprojekt)
Anhand eines Beispielprojekts, in dem mit handgeschriebenen Briefen des Sprachwissenschaftlers Hugo Schuchardt (1842-1927) aus dem 19. Jahrhundert gearbeitet wird, soll nachfolgend ein möglicher Arbeitsablauf mit Transkribus Lite beschrieben werden. In einem ersten Schritt soll überprüft werden, ob es ein öffentliches HTR-Modell gibt, mit dem die Briefe Schuchardts mit einer für uns annehmbaren Zeichenfehlerrate (“Character Error Rate”, CER) transkribiert werden können. Da sich zeigen wird, dass dies nicht der Fall ist, werden wir unser eigenes Modell trainieren. In einem letzten Schritt werden wir das Textmaterial mittels Transkribus-Lite-Editor noch ansatzweise unter der Verwendung TEI-konformer Tags annotieren und letztlich als TEI-XML-Dateien exportieren, um diese dann mittels anderer Tools weiter bearbeiten zu können.
Allgemeiner Transkribus-Workflow
Der allgemeine Transkribus-Workflow kann wie folgt visualisiert werden:
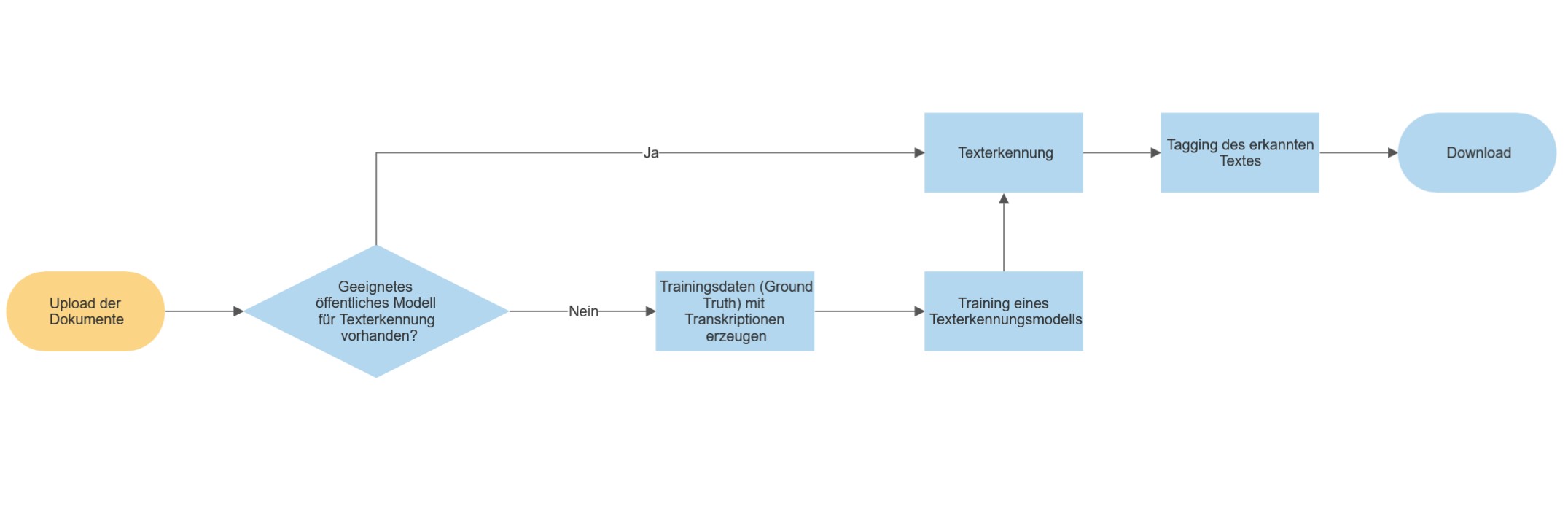
- Start: Upload der Dokumente → Überprüfung, ob eines der öffentlichen Modelle für die automatische Texterkennung geeignet ist:
- JA: Texterkennung → Tagging des erkannten Textes → Download
- NEIN: Layouterkennung → Trainingsdaten (“Ground Truth”) mittels Transkriptionen erzeugen→ Training eines Texterkennungsmodells → Texterkennung → Tagging des erkannten Textes → Download
1. Registrierung
- Um Transkribus Lite nutzen zu können, ist eine Registrierung erforderlich, wobei Namen und E-Mail-Adresse angegeben werden müssen.
- Bei Registrierung erhält man 500 nicht teilbare Credits zur Verfügung gestellt, mit denen 500 handgeschriebene oder 3000 gedruckte Seiten automatisch transkribiert werden können.
2. Transkribus Lite - Benutzeroberfläche
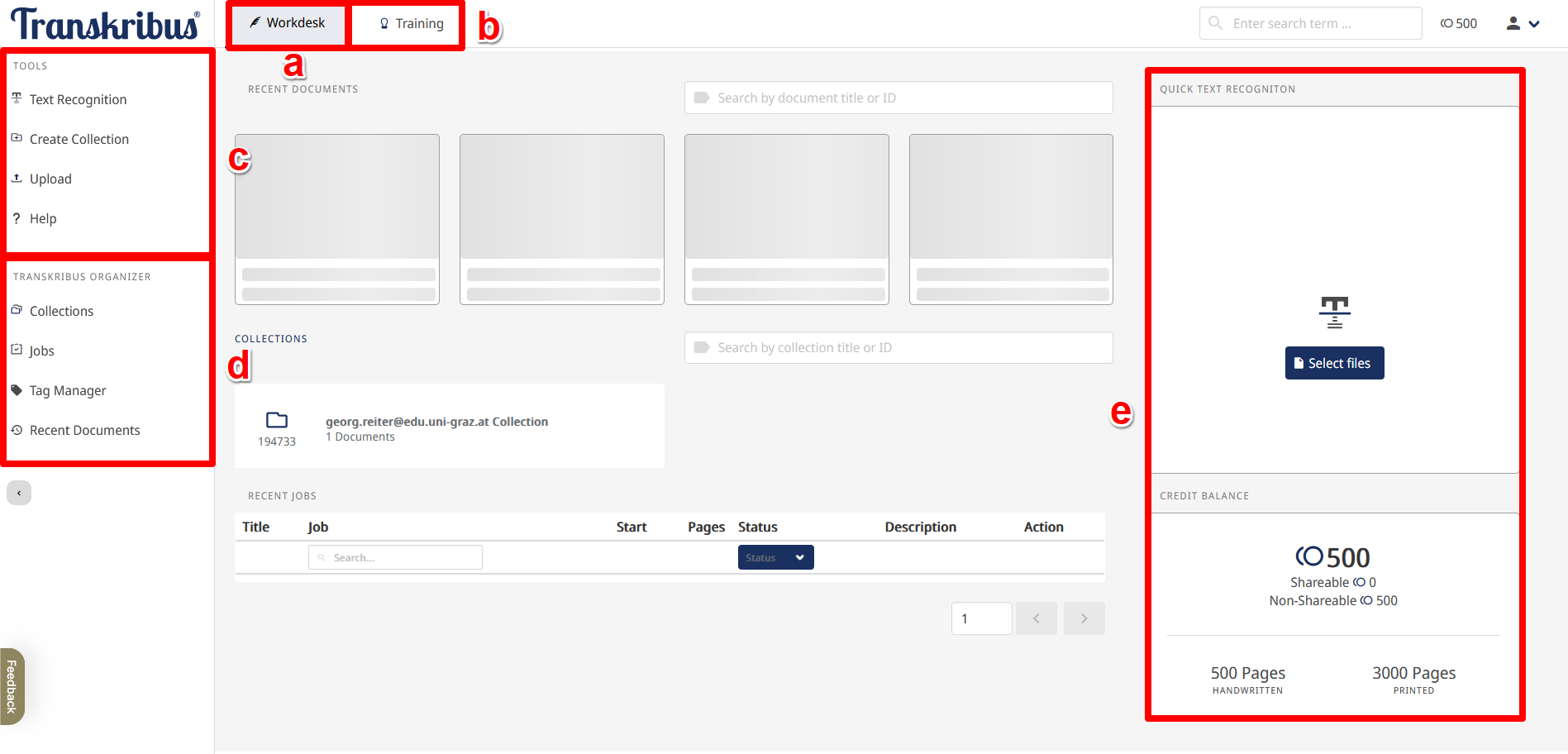
- Dashboard: Nach dem Einloggen findet man sich im Transkribus-Lite-Dashboard wieder. Hier können die Tabs “Workdesk” und “Training” ausgewählt werden, wobei per default “Workdesk” selektiert ist.
- “Workdesk” (Abb. 3): Der Workdesk (Auswahlschaltfläche siehe Abb. 3: a) ist die Arbeitsumgebung, die Zugang zu den elementaren Funktionen von Transkribus bietet:
- Linke Menüleiste: “Tools” (Abb. 3: c) (“Text-Erkennung”, “Sammlung erstellen”, “Hochladen”, “Hilfe”) und “Transkribus Organizer” (Abb. 3: d) (“Sammlungen”, “Jobs”, “Tag Manager”, “Aktuelle Dokumente”)
- Rechte Menüleiste: Schnelle Texterkennung und Übersicht über das Creditsaldo (Abb. 3: e)
- “Training” (Abb. 3: b): Hier können Modelle für die Layout- und Texterkennung trainiert werden
- “Workdesk” (Abb. 3): Der Workdesk (Auswahlschaltfläche siehe Abb. 3: a) ist die Arbeitsumgebung, die Zugang zu den elementaren Funktionen von Transkribus bietet:
3. Projekteinrichtung
- Sammlungen: Das Anlegen einer Sammlung ist nötig, um die Layout und/oder Texterkennung durchführen zu können. Eine Sammlung ist in Transkribus ein Ordner, der alle Dokumente eines bestimmten Projekts enthält.
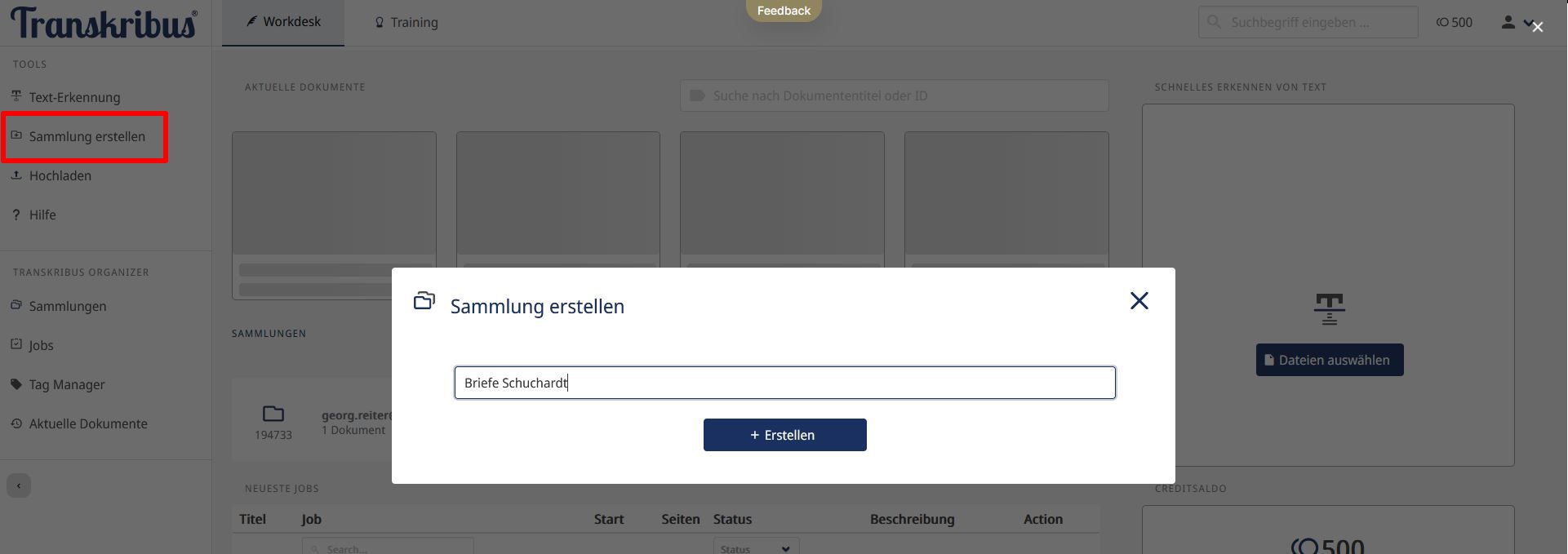
- Anlegen einer Sammlung (Abb. 4): Eine Sammlung wird im Workdesk über die Schaltfläche “Sammlung erstellen” in der linken Menüleiste angelegt. Wir legen nun eine Sammlung mit dem Namen “Briefe Schuchardt” an. Eine angelegte Sammlung kann unter der Schaltfläche “Sammlungen” wieder gelöscht oder bearbeitet werden (Änderung der Metadaten wie dem Namen der Sammlung oder einer kurzen Beschreibung)
4. Erste Aktionen innerhalb einer Sammlung
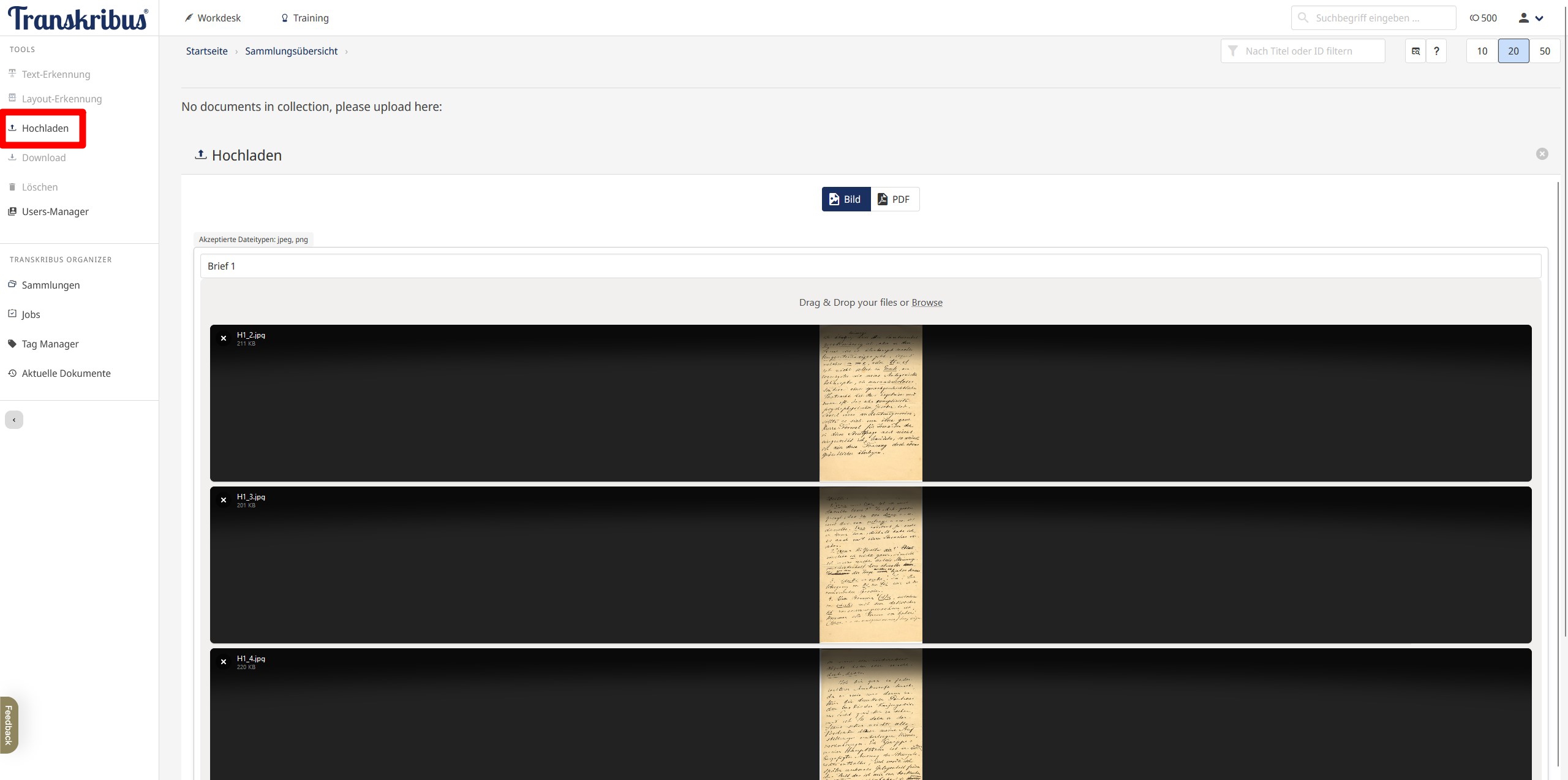
- Upload von Dokumenten: Wir navigieren nun über die linke Toolbar, bei der wir auf “Sammlungen” klicken, zur neu angelegten Sammlung. Die erste Aktion innerhalb einer Sammlung ist das Hochladen von Dokumenten, auf die in weiterer Folge die Layout- und Texterkennung angewandt werden kann oder die transkribiert werden können. Ein Dokument ist in Transkribus Lite eine Menge an Bildern, die in einem bestimmten Zusammenhang stehen (z. B. ein Manuskript, ein Vertrag, ein Brief). Möglich ist der Upload von Bildern (JPEG/PNG) oder PDFs. Alle gemeinsam hochgeladenen Dateien werden als ein einzelnes Dokument angesehen, jedes einzelne Bild bzw. jede Seite eines PDFs wird zu einer Seite des Dokuments. Für unsere Zwecke ist jeder Brief Schuchardts, der aus mehreren Bildern besteht, ein Dokument, deshalb laden wir die jeweils zusammengehörigen Bilddateien separat hoch (“H1_1” bis “H1_4”, “H2_1 bis “H2_18” usw.). Wir geben den einzelnen Dokumenten die Namen “Brief 1”, “Brief 2” usw. Durch einen Klick auf die drei Punkte kann der Dokumentname nachträglich geändert werden, ebenso können Metadaten wie etwa “Autor” hinzugefügt werden.
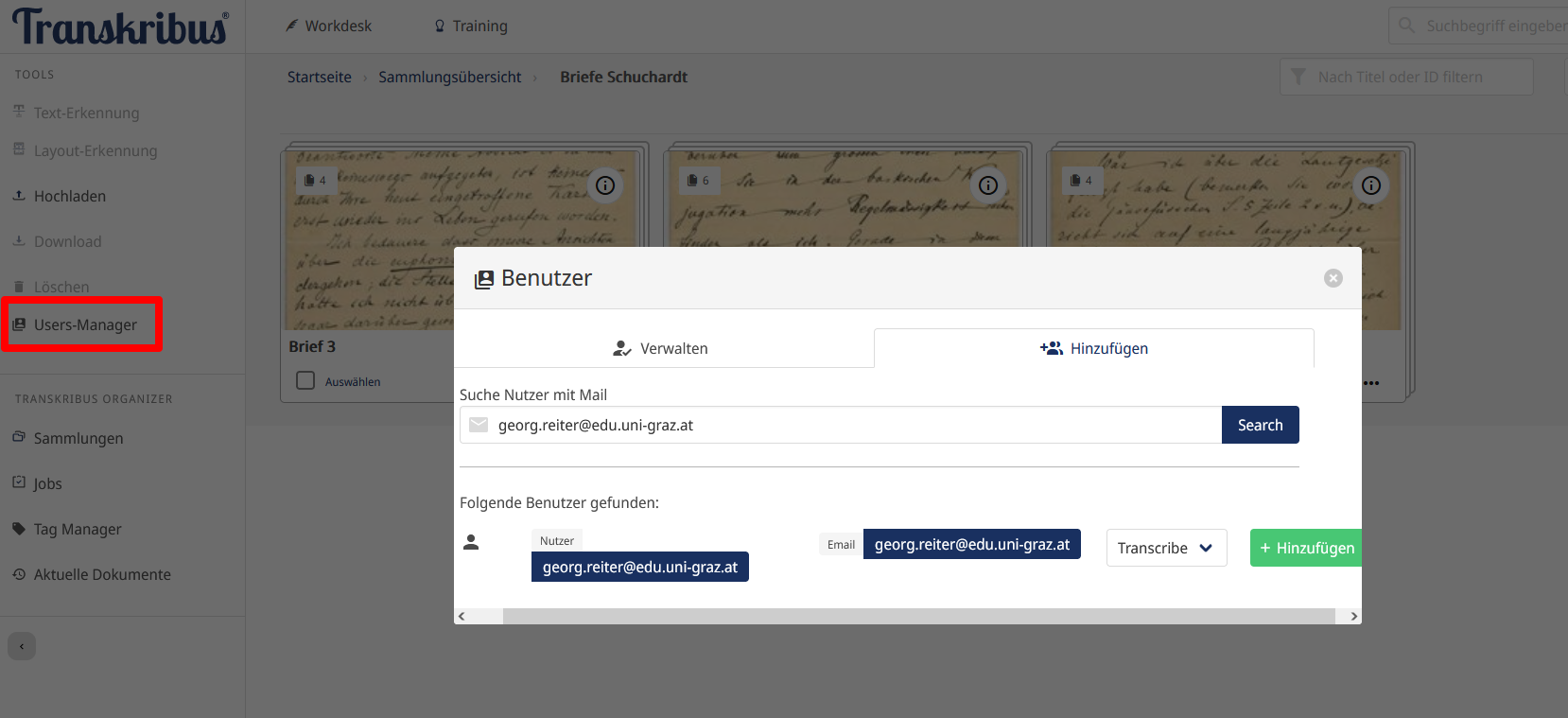
- Hinzufügen von Nutzer:innen: Im Transkribus Organizer in der linken Menüleiste können unter der Schaltfläche “User-Manager” andere Nutzer:innen zur Sammlung hinzugefügt werden, sodass gemeinschaftlich an einer Sammlung gearbeitet werden kann. Die möglichen Rollen sind “Owner”, “Editor” und “Transcriber”, wobei in absteigender Reihenfolge der “Owner” einer Sammlung über die meisten Rechte verfügt. Die Berechtigungen und ihre Abstufungen können hier eingesehen werden. Damit das Hinzufügen möglich ist, müssen die anderen Nutzer:innen bereits registriert sein und bei der Suche muss deren exakte E-Mail-Adresse angegeben werden. Wir fügen nun eine:n Nutzer:in hinzu und vergeben die Rolle “Transcribe”, sodass uns diese Person bei der Transkription behilflich sein kann.
5. Durchführen von Texterkennung
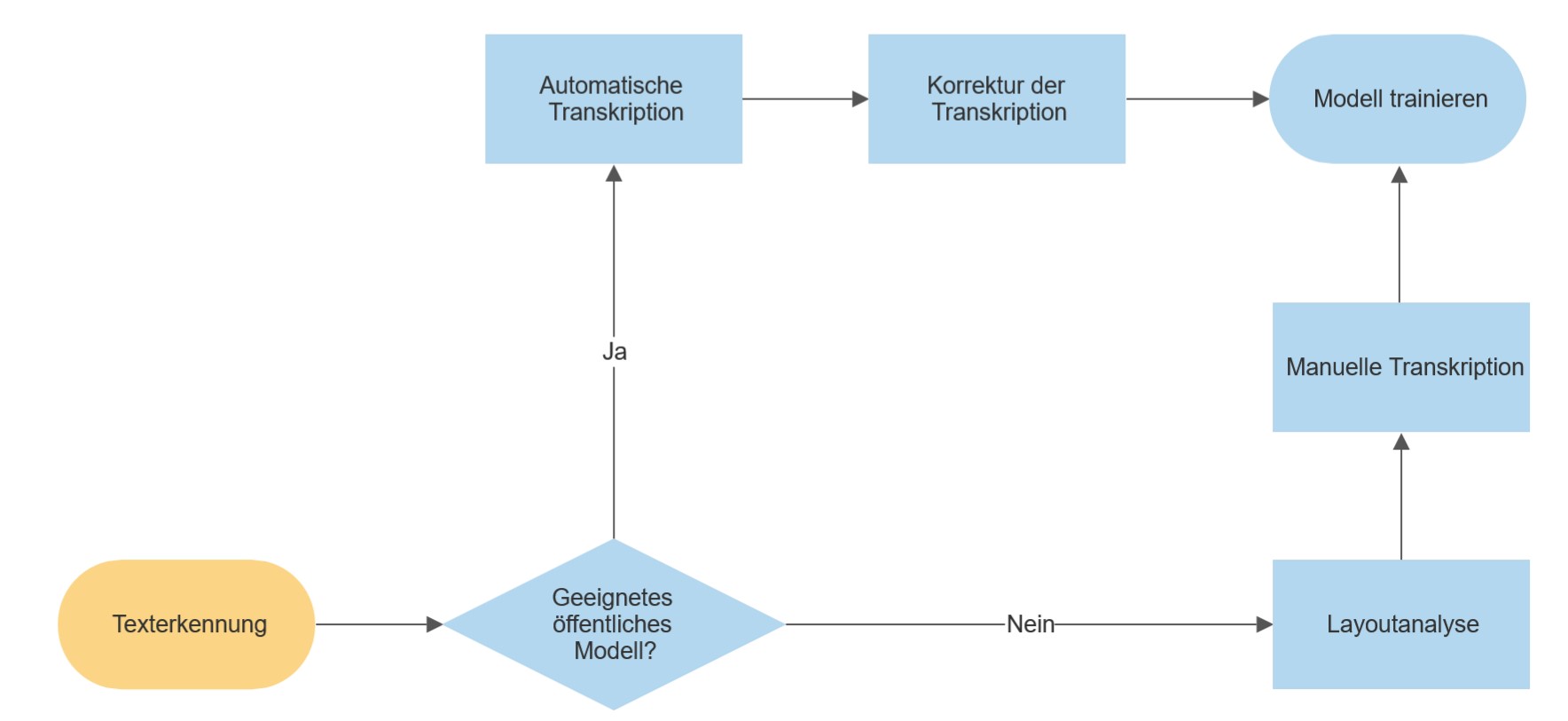
- Will man Text von Transkribus Lite transkribieren lassen, ist es am sinnvollsten, zunächst zu überprüfen, ob bereits eines der öffentlich verfügbaren Modelle für die eigenen Zwecke geeignet ist und eine tolerierbare Zeichenfehlerrate (“Character Error Rate”, CER) aufweist, sodass nur geringe Nachkorrekturen des Textmaterials notwendig sind. Nur falls dies nicht der Fall ist, ist das Trainieren eines eigenen Modells notwendig. Allgemein kann der Workflow für das Training eines Texterkennungsmodells wie folgt visualisiert werden:
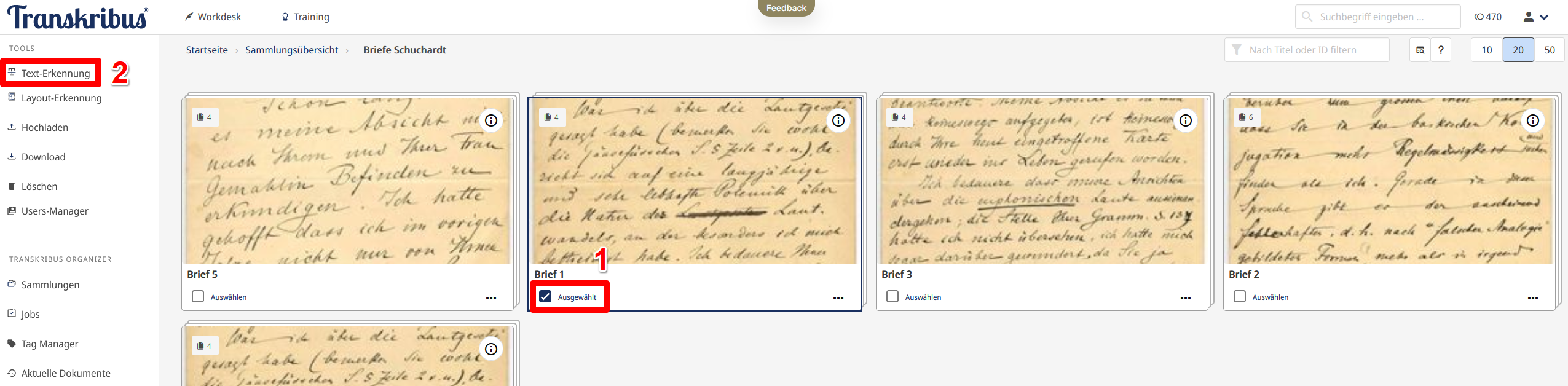
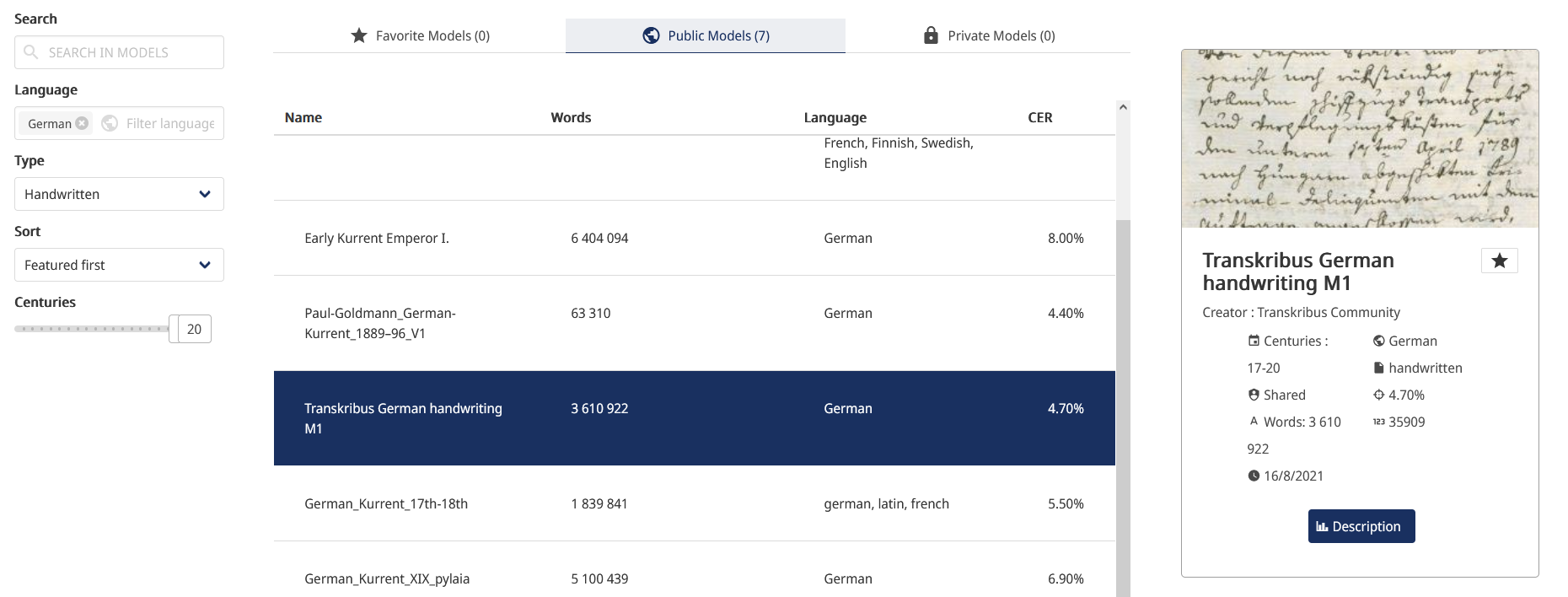
- Wir wollen also nun feststellen, wie gut die Texterkennung der öffentlichen Modelle, angewandt auf die Handschrift Hugo Schuchardts, funktioniert. Dazu wählen wir nun in der Sammlungsübersicht das Dokument “Brief 1” aus und klicken in der linken Menüleiste auf “Texterkennung” (Abb. 8). Nun werden wir auf eine neue Seite weitergeleitet, auf der wir das Modell, das zur Texterkennung verwendet werden soll, auswählen müssen.
- Da über 100 öffentliche Modelle zur Auswahl stehen, wenden wir die links selektierbaren Filterkriterien an, um die Anzahl an potentiell applikablen Modellen einzuschränken. Bei “Sprache” wählen wir “Deutsch”, bei “Typ” “Handschriftlich” und bei “Jahrhunderte” den Zeitraum 19. bis 20. Jahrhundert. Es ist wichtig, dass diese auf das jeweilige Textmaterial zugeschnittene Auswahl getroffen wird, damit die Auswahl auf die am besten geeigneten Modelle eingeschränkt wird. Nun werden nur mehr wenige Modelle angezeigt (Abb. 9), wir entscheiden uns für das Modell “Transkribus German handwriting M1”, da die anderen Modelle primär für Kurrentschrift ausgelegt zu sein scheinen (Weiterführende Informationen zu den Modellen erhält man durch einen Klick auf “Beschreibung”). Das Modell weist eine Zeichenfehlerrate (Character Error Rate (CER)) von 4,7 % auf, d. h. es würden von 100 Zeichen ca. 5 falsch erkannt werden. Nach dem Klick auf “Start” wird der Job ausgeführt und wir können unter der Schaltfläche “Jobs” seinen Fortschritt verfolgen.
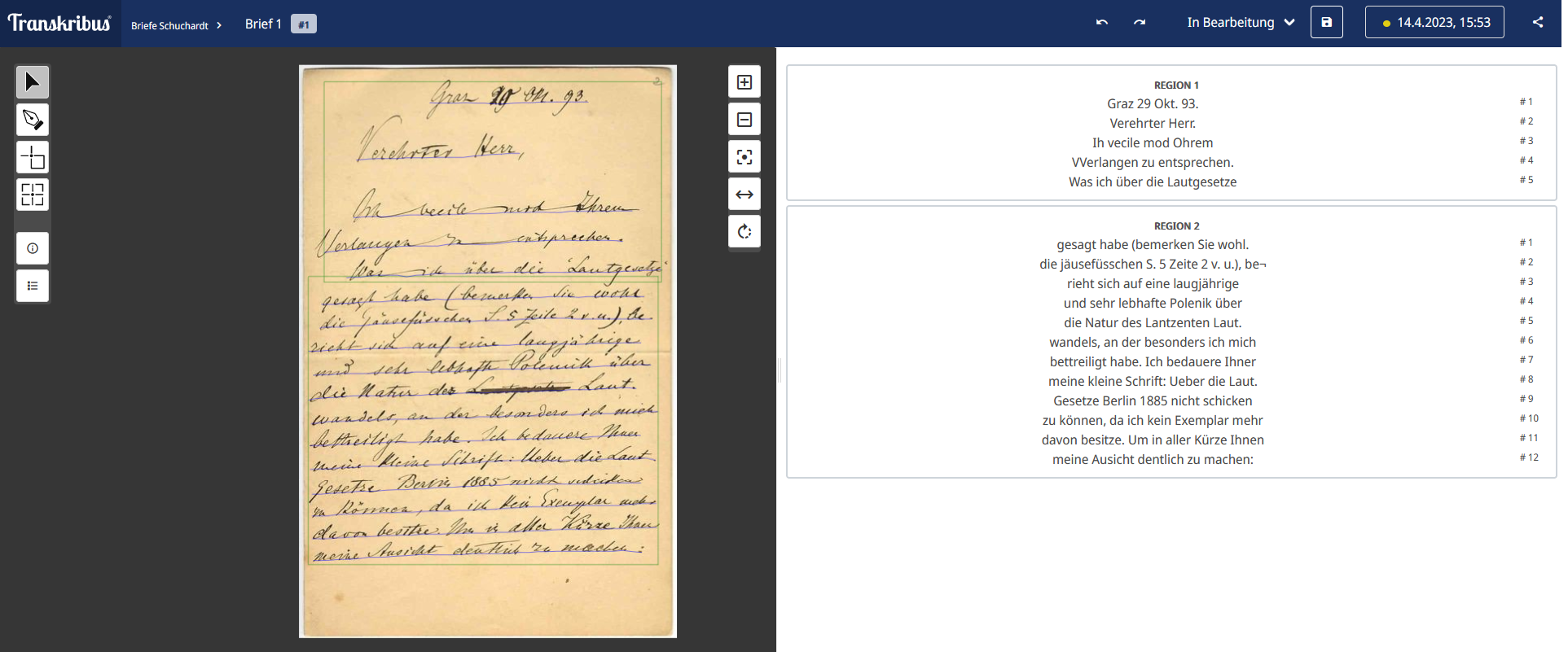
- Um zu sehen, wie gut die Texterkennung funktioniert hat, navigieren wir nun, nachdem der Job abgeschlossen ist, in das Dokument und klicken auf die erste Seite. Dabei öffnet sich der Editor mit Bild-Text-Synopse, wobei links das Faksimile angezeigt wird und rechts die automatisch erstellte Transkription (Abb. 10). Wie zu erkennen ist, liegt die CER in unserem Fall augenfällig deutlich bei über 5 %. Wie sich außerdem auf der ersten und besonders auf den weiteren Seiten des Dokuments zeigt, hat auch die Layouterkennung bei unserem Material nicht optimal funktioniert. So wurde z. B. die zweite Seite des Briefes ohne erkennbaren Grund in 3 Zonen unterteilt (Abb. 11).
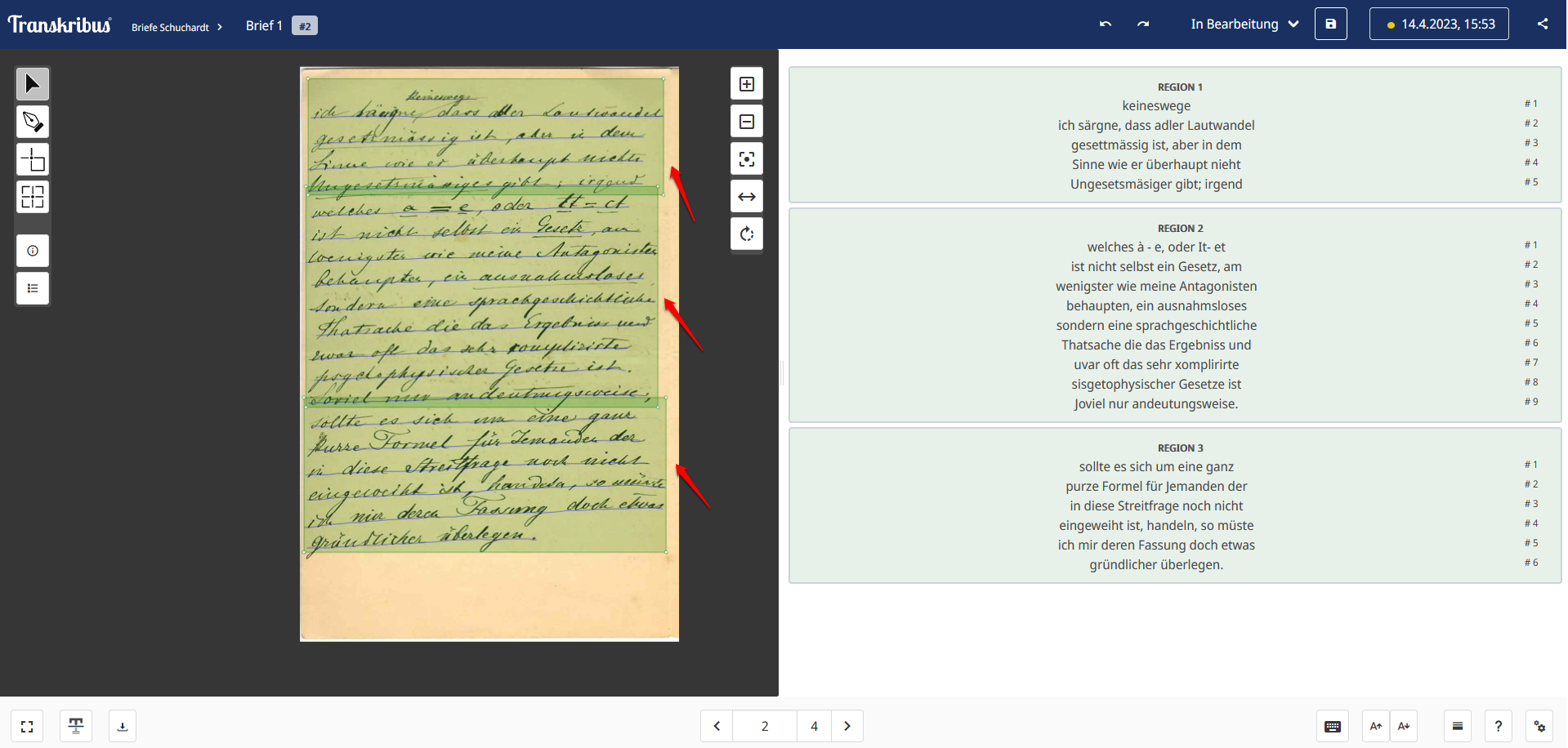
- Die Texterkennung mittels des Modells “Trankribus German handwriting M1” fallen zwar nicht sehr schlecht aus, dennoch wollen wir erproben, ob es möglich ist, ein eigenes Modell zu trainieren, mit dem die Briefe Schuchardts mit einer niedrigeren CER transkribiert werden können.
6. Training eines Texterkennungsmodells
- Zum Erstellen von Trainingsdaten gibt es, wie es im Flowchart (siehe oben Abb. 7) ersichtlich ist, also 2 Wege:
- Händisch: Zunächst wird eine Layouterkennung durchgeführt, danach der Text Zeile für Zeile transkribiert. Zuletzt werden die Transkripte als Trainingsdaten gespeichert und ein eigenes Texterkennungsmodell trainiert.
- Halb automatisch, halb händisch: Hier wird zunächst ein öffentliches Modell verwendet und überprüft, ob die automatische Transkription zu einigermaßen korrekten Ergebnissen führt. Im nächsten Schritt werden die automatischen Transkriptionen händisch korrigiert und dann als Trainingsdaten gespeichert. Zuletzt wird auf Basis dieser Trainingsdaten ein eigenes Texterkennungsmodell trainiert.
- Für das Training eines Texterkennungsmodells werden von Transkribus 25-75 Seiten (5.000-15.000 Wörter) als Trainingsdaten (“Ground Truth”) benötigt bzw. empfohlen, bei handgeschriebenen Texten sollten es mindestens 10.000 Wörter pro Hand sein. Als Trainingsdaten werden in Transkribus die Faksimiles und die mit ihnen korrespondierenden fehlerfreien und genauen Transkriptionen bezeichnet, die in weiterer Folge für das Training der Texterkennungsmodelle verwendet werden. Generell gilt: Je mehr Trainingsdaten vorhanden sind, desto erfolgreicher verläuft das Modelltraining.
- Momentan ist es in Transkribus Lite leider noch nicht möglich, bereits außerhalb transkribierten Text zeilenübergreifend einzufügen - Es können bisher nur einzelne Zeile angewählt und befüllt werden, es gibt keine Möglichkeit, Teile des Textes in die nächste Zeile umzubrechen (Abb. 12).
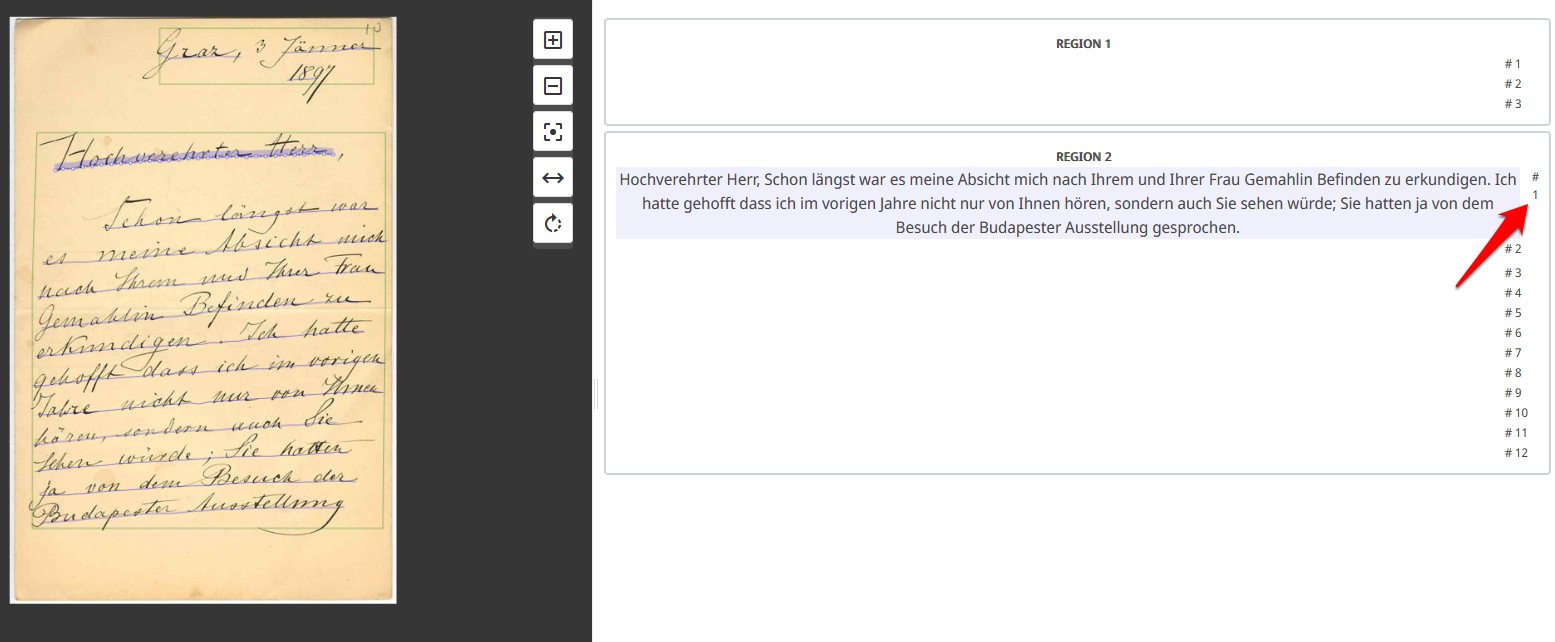
- Wir befinden uns also in einer etwas misslichen Lage und entscheiden uns, da die Texterkennung mit dem von uns gewählten öffentlichen Modell zumindest einigermaßen brauchbare Ergebnisse liefert, für den halb automatischen, halb händischen Zugang, da die Korrektur von falsch erkanntem Text in unserem Fall weniger Zeit in Anspruch nimmt, als ihn händisch von Grund auf zu transkribieren. Dazu müssen wir noch die automatische Texterkennung auf die Dokumente Brief 2 bis 18 anwenden. Nachdem dies erledigt ist, gleichen wir die automatisch transkribierten Texte mit unserer bereits vorhandenen Transkription ab und bessern die falsch erkannten Zeichen bzw. Wörter aus. Nach dem Abschluss der Korrekturen können wir uns nun dem Training eines auf Hugo Schuchardts Handschrift zugeschnittenen Texterkennungsmodells widmen.
- Um ein Texterkennungsmodell zu trainieren, wählen wir das Tab “Training” und klicken auf “Text-Erkennung”. Danach wählen wir die Sammlung “Briefe Schuchardt” aus (Abb. 13).
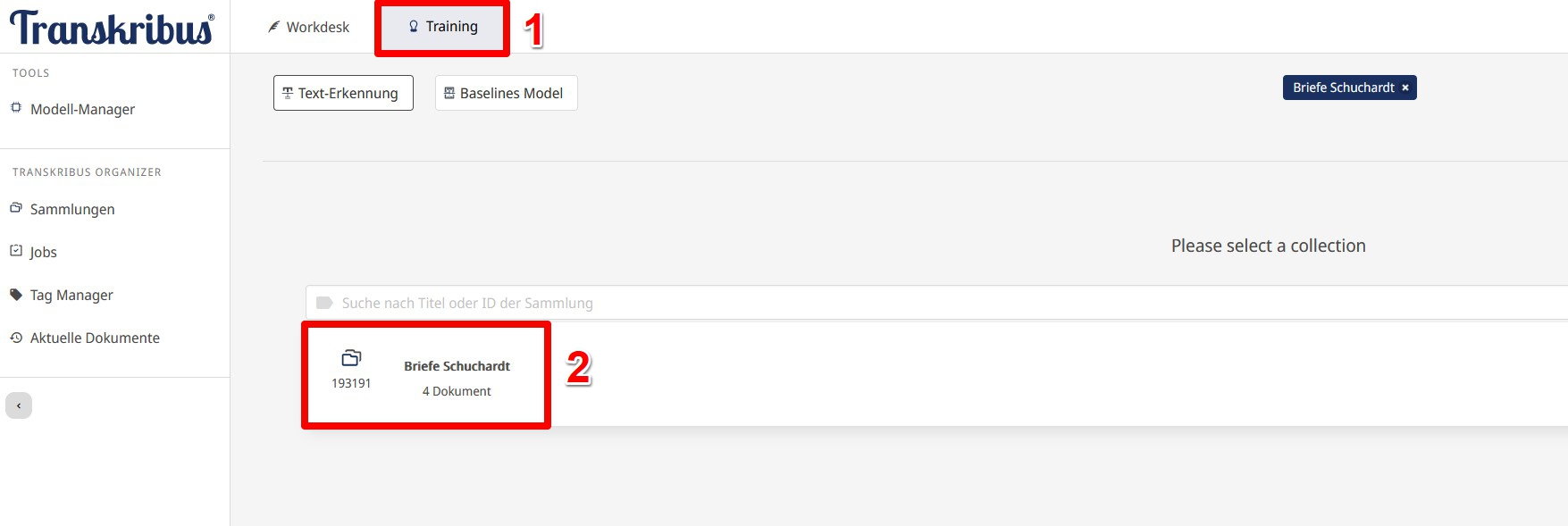
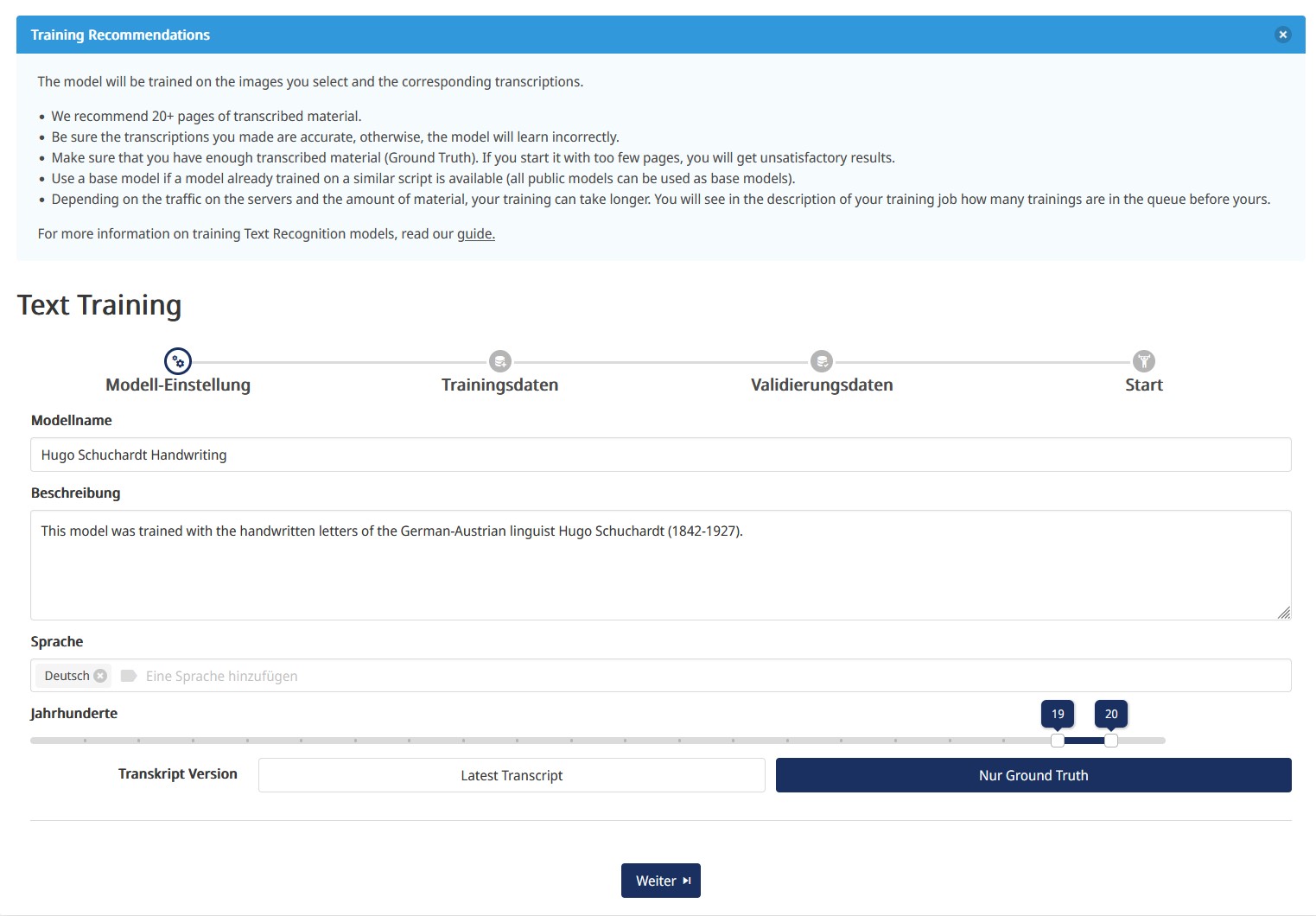
- Nun werden wir weitergeleitet und müssen nun zunächst einige Metadaten für unser Modell eingeben (Abb. 14): Modellnamen, Beschreibung, Sprache(n) und Zeitspanne, die unsere Daten umfassen. Zuletzt müssen wir noch die Transkriptversion auswählen. Hier können wir uns zwischen “Latest Transcript” und “Nur Ground Truth” entscheiden. Entscheiden wir uns für “Ground Truth” sind im nächsten Schritt nur die Seiten, deren Status wir als “Trainingsdaten” festgelegt haben, anwählbar, bei “Latest Transkript” können alle Seiten, egal welchen Transkriptionsstatus wir ihnen früher zugewiesen haben, ausgewählt werden.
- Auswahl der Trainings- und Validierungsdaten: In den nächsten beiden Schritten müssen die Dokumente bzw. Seiten unserer Sammlung, mit denen wir unser Modell trainieren wollen, in ein “Training Set” und ein “Validation Set” aufgeteilt werden. Das Training Set umfasst jene Menge an Material, mit denen das Modell trainiert wird. Die Dokumente des Validation Set werden nicht im Training berücksichtigt, sondern dazu verwendet, die Genauigkeit des Modells zu überprüfen.
- Zunächst wählen wir die Trainingsdaten aus. Hier können wir die Dokumente gesamt auswählen oder uns für einzelne Seiten innerhalb der Dokumente entscheiden. Wir wählen Brief 1 bis 18 aus, da wir so die von Transkribus empfohlene Anforderung von mindestens 10.000 transkribierten Wörtern bei handgeschriebenen Texten erreichen und klicken auf “Weiter”.
- Im nächsten Schritt wählen wir die Validierungsdaten aus. Die Validierungsdaten sollten nach Empfehlungen von Transkribus 10 % der Trainingsdaten umfassen und repräsentativ für die Dokumente in unserer Sammlung sein, denn sonst könnte es zu einem Bias bei der Messung der Performance des Modells kommen. Die Dokumente bzw. Seiten für die Validierungsdaten können händisch ausgewählt oder automatisch (2 %, 5 % oder 10 %) zugewiesen werden. Nur Seiten, die nicht bereits den Trainingsdaten zugewiesen wurden, können ausgewählt werden. Wir folgen den Empfehlungen von Transkribus und entscheiden uns für eine automatische Zuweisung von 10 % und klicken auf “Weiter”.
- Erweiterte Einstellungen: In der letzten Ansicht vor dem Start des Trainings sehen auf einer Seite nochmals die Metadaten unseres Modells und können sie gegebenenfalls ändern, ebenso werden die ausgewählten Trainings- und Validierungsdaten nochmals gegenübergestellt angezeigt. Darunter findet sich ein mit “Erweitert” betitelter Reiter, der noch einige Einstellungen verbirgt:
- Anzahl an “Epochs”: Zunächst können wir die Anzahl an ‘Epochen’ (“Epochs”) verändern, die standardmäßig auf 250 eingestellt ist. Diese Zahl gibt an, wie oft Trainings- und Validierungsset maximal evaluiert werden. Das Training wird automatisch gestoppt, wenn die niedrigstmögliche Zeichenfehlerrate (“Character Error Rate” (CER)) erreicht wurde. Transkribus empfiehlt, den Wert zunächst auf 250 zu belassen.
- Early Stopping: Weiters können wir den “Early Stopping”-Parameter modifizieren, der standardmäßig auf 20 eingestellt ist. Ein Wert von 20 bedeutet, dass, falls nach 20 Epochen die CER nicht mehr sinkt, das Training beendet wird. Transkribus empfiehlt an diesem Punkt ein heterogenes Validierungsset, das repräsentativ für das Trainingsset ist, da sonst das Training zu früh abbrechen könnte. Außerdem wird empfohlen, diesen Wert nur dann zu erhöhen, wenn das Validierungsset klein ist, um zu verhindern, dass das Training abgebrochen wird, bevor das Modell alle Trainingsdaten verarbeitet hat. Auch hier empfiehlt Transkribus, den Wert zunächst beizubehalten.
- Auswahl eines Basismodells: Wir können auch ein bereits vorhandenes öffentliches Modell als Basismodell auswählen, das als Ausgangspunkt für das Training verwendet werden soll, was bedeuten würde, dass das unser Modell nicht von Grund auf lernen muss. Wird mit einem Basismodell trainiert, genügen möglicherweise weniger Trainingsdaten. Es ist allerdings nicht immer garantiert, dass die Verwendung eines Basismodells zu besseren Ergebnissen führt, sondern es muss im spezifischen Fall getestet werden. Wir entscheiden uns voerst gegen ein Baselinemodell als Trainingsgrundlage, werden aber zum Vergleich auch zwei weitere Modelle mit jeweils unterschiedliche Baselinemodellen trainieren (siehe unten).
- “Reverse Text (RTL)”: Zuletzt können wir noch wir noch “Reverse Text (RTL)” auswählen, falls die Schreibrichtung unseres Materials von rechts nach links ist.
- Wir behalten also alle erweiterten Einstellungen bei und klicken auf “Training starten”.
- Ergebnis des Modelltrainings: Um die Trainingsergebnisse zu betrachten, wechseln wir zum Modell-Manager. Dazu klicken wir auf das Tab “Training” und wählen dann links unter “Tools” diesen aus (Abb. 15).
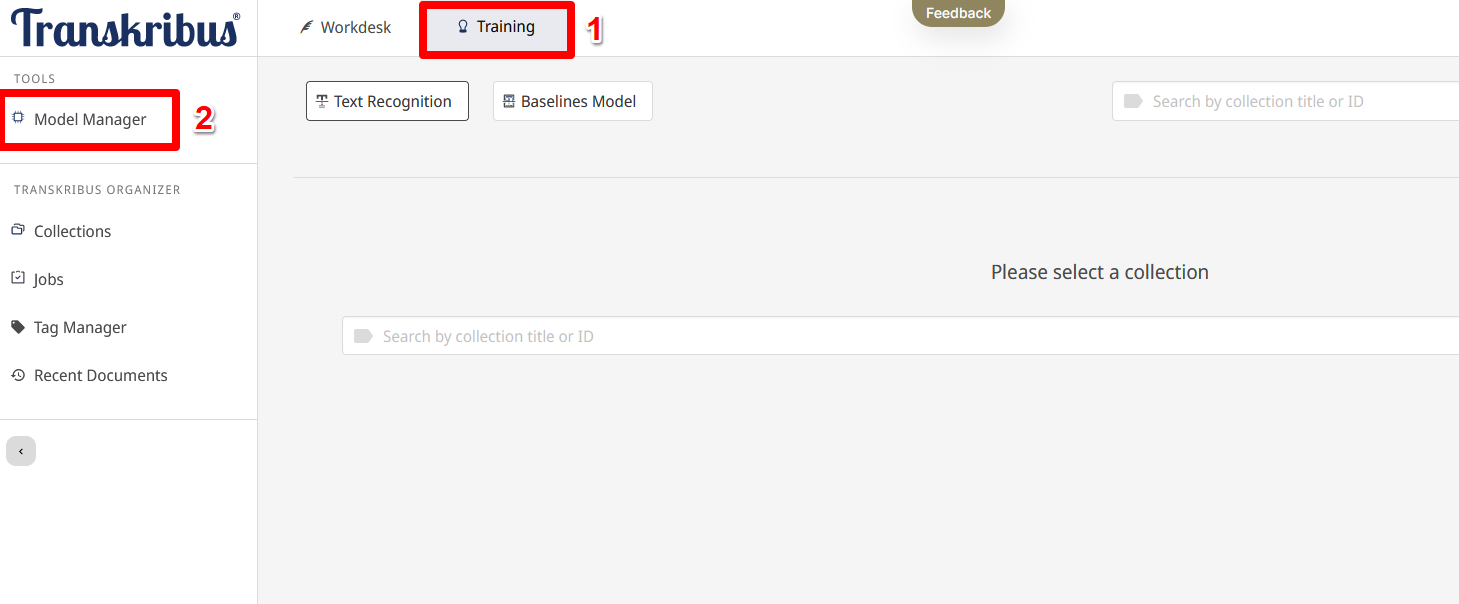
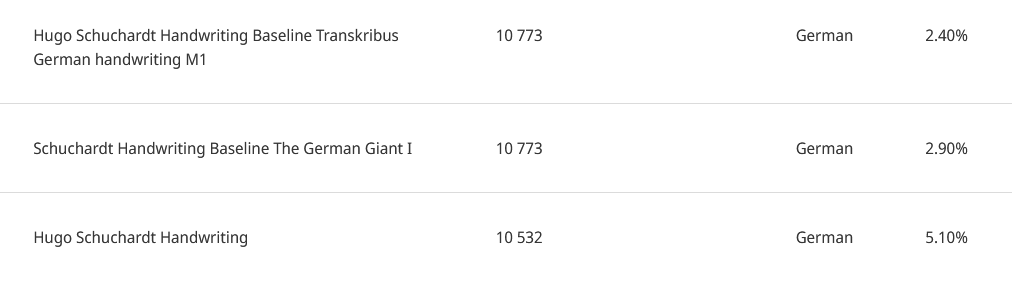
Im Modellmanager (Abb. 15) gelangen wir schließlich über das Tab “Private Modelle” zu den von uns trainierten Modellen. Insgesamt haben wir, um zu überprüfen, ob bei der Verwendung von Baselinemodellen als Trainingsgrundlage eine niedrigere CER erreicht werden kann, 3 Modelle trainiert. Bei ersten Modell wurde auf ein Baselinemodell verzichtet, bei den anderen wurden die beiden großen öffentlichen und für deutschsprachige handgeschriebene Texte ausgelegten Modelle “Transkribus German handwriting M1” bzw. “The German Giant I” als Baselinemodelle verwendet. In unserem Fall erzielt die Verwendung von Baselinemodellen ein deutlich besseres Ergebnis: Die CER ist im Vergleich zu den baselinefreien Modellen im besten Ergebnis mehr als halbiert: 2,4 % vs. 5,1 % (siehe Abb. 16). Allgemein fallen die Ergebnisse sehr gut aus, gemäß der Angaben von Transkribus können Modelle mit einer geringeren CER als 10 % als sehr effizient für die automatische Transkription angesehen werden. Als eine gute CER im Fall von mit handgeschriebenen Texten trainierten Modelle wird ein Intervall zwischen 2 % und 8 % angegeben, d. h. unsere Modelle erzielen durchwegs gute Ergebnisse.
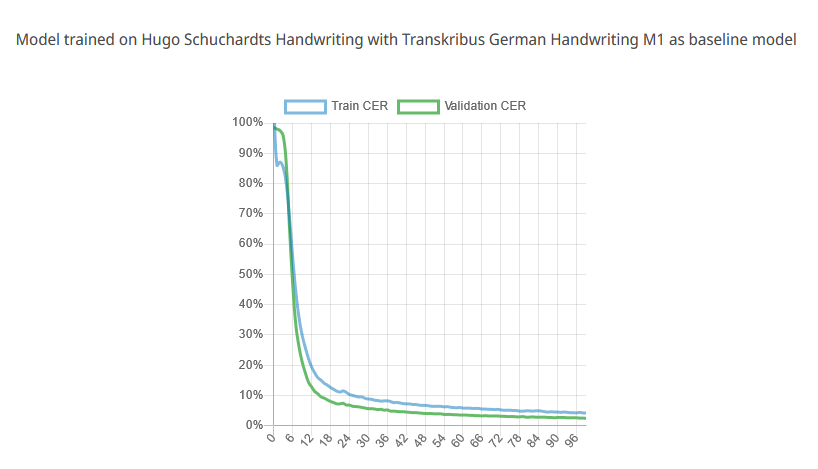
Wenn wir ein Modell auswählen, können wir uns durch einen Klick auf “Beschreibung” die Lernkurve anzeigen lassen (Abb. 17). Auf der Y-Achse ist die CER in Prozent angegeben, auf der X-Achse die Anzahl an ‘Epochen’ (“Epochs”). In unserem Fall wurde das Training kurz nach 96 Epochs abgebrochen, da sich die CER nicht mehr verringerte. Die blaue Linie des Graphen zeigt den Trainingsfortschritt an, die grüne den Fortschritt der Evaluation der Validierungsdaten. Die grüne Linie des Graphen ist gemäß der Angaben von Transkribus repräsentativer, da sie anzeigt, wie gut das Modell bei neuen Seiten, die nicht im Trainingsmaterial inkludiert waren, abschneiden sollte.
7. Die Texteditoransicht
- Nachdem wir unser Modell trainiert haben, wollen wir noch den Texteditor von Transkribus erproben und unsere Dokumente annotieren. Zum Texteditor gelangen wir, indem wir über die linke Menüleiste “Sammlungen” auswählen, in unsere Sammlung navigieren, ein Dokument (z. B. “Brief 1”) öffnen und dann eine Seite des Dokuments anklicken. Nun öffnet sich der Editor mit Bild-Text-Synopse (Abb. 18).
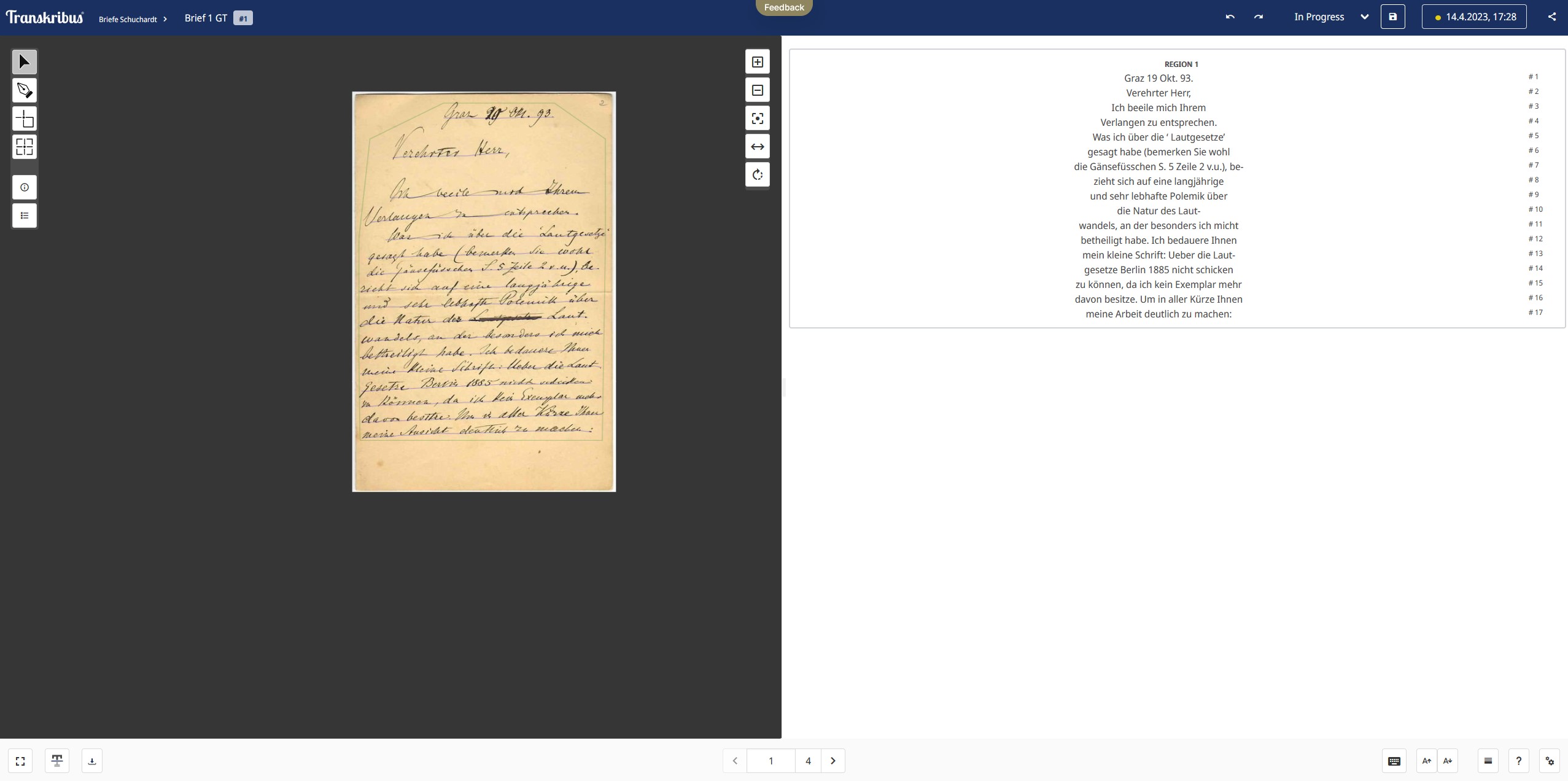
- In der Standardansicht findet sich links im Bild das Faksimile und rechts der Texteditor. Die Ansicht kann über die untere Menüleiste umgestellt werden, sodass sich oben das Faksimile und unten der Texteditor findet.
- Wichtige Optionen im Editorfenster (rechts):
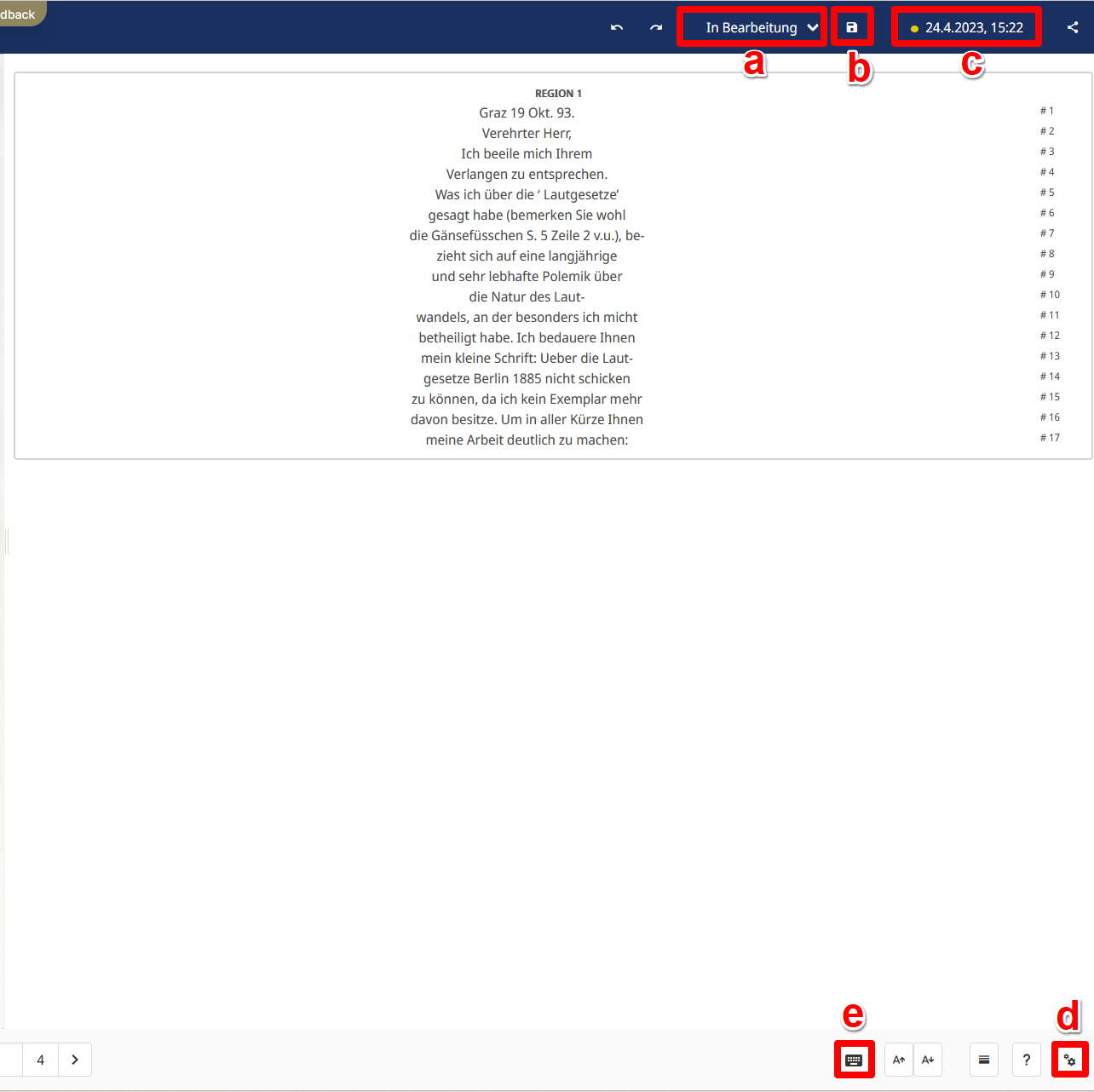
- Festlegen des Bearbeitungsstatus: Im rechten oberen Eck kann Bearbeitungsstatus der Seite festgelegt werden (Abb. 18: a): “In Bearbeitung”, “Erledigt” (die Seite wurde transkribiert), “Final” (die Seite wurde transkribiert und einem Review unterzogen) und “Trainingsdaten” (die Transkription ist so korrekt wie möglich transkribiert und kann zum Modelltraining verwendet werden).
- Speichern: Mit dem dem Diskettensymbol (Abb. 19: b) kann gespeichert werden
- Versionskontrolle: Die Schaltfläche mit Datums- und Zeitangabe (Abb. 16: c) dient der Versionskontrolle. Mittels ‘Speicherständen’ kann auf frühere und von dort aus gesehen spätere Versionen zugegriffen werden werden.
- Konfiguration: Über das Zahnradsymbol (Abb. 19: d) können verschiedene Einstellungen vorgenommen werden und so z. B. das Verhalten und Layout des Editors an die eigenen Bedürfnisse angepasst werden. Es ist aber hier auch möglich, eigene Texttags hinzuzufügen oder bereits vorhandene zu entfernen. Ebenso kann die Sichtbarkeit der Strukturtags gesteuert werden.
- Virtuelles Keyboard: Das Keyboardsymbol (Abb. 19: e) blendet das Virtuelle Keyboard ein, über das Unicode-Zeichen eingefügt werden können . Dazu müssen die gewünschten Unicode-Bereiche zunächst über die Konfigurationsschaltfläche (Zahnradsymbol) ausgewählt werden.
- Wichtige Optionen im Faksimilefenster (links):
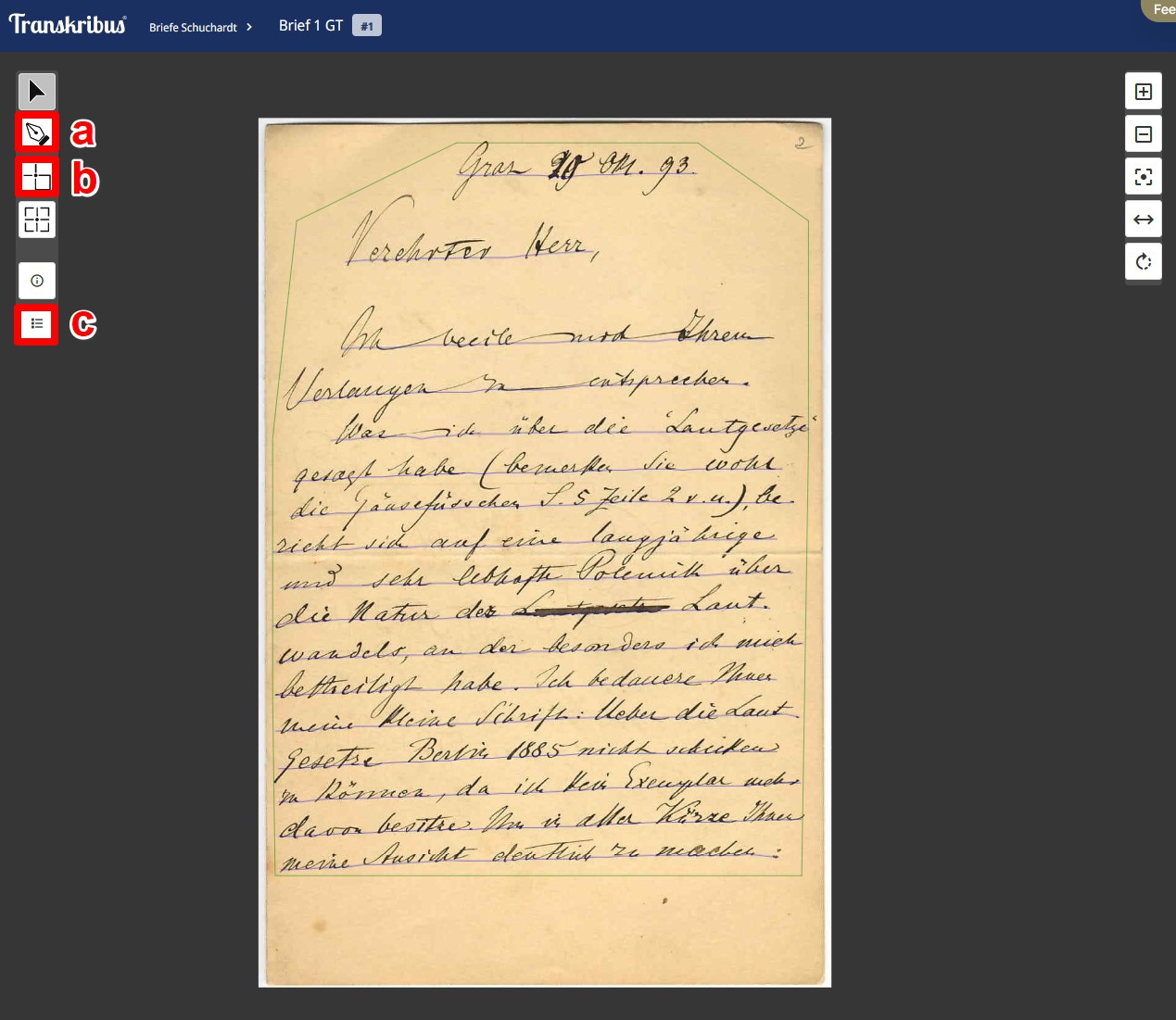
- Hinzufügen von Zeilenlinien: Über das Füllfedersymbol (Abb. 19: a) können Zeilenlinien hinzugefügt werden. Wird eine Linie hinzugefügt, erscheint die mit ihr korrespondierende Zeile rechts im Editorfenster. Ausgewählte Zeilen können auch über die Entfernen-Taste auf der Tastatur gelöscht werden.
- Aktionen mit Regionen:
- Mittels Button (Abb. 19: b) können Regionen hinzugefügt werden
- Bereits bestehende Regionen können geteilt werden: Dazu muss die Region mittels Klick ausgewählt werden, nach einem Rechtsklick können dann die Teilungsoptionen ausgewählt werden: Horizontal, vertikal oder benutzerdefiniert (Im letzten Fall kann mittels Pfeiltasten die Teilungslinie gedreht werden.).
- Zusammenfügen von Regionen: Dazu werden mit Strg und Mausklick mehrere Regionen markiert, nach einem Rechtsklick können sie mit “Merge shapes” zusammengeführt werden.
- Layoutbutton: Nach einem Klick auf den Layoutbutton (Abb. 19: c) öffnet sich ein Fenster, in dem die Struktur des Dokuments (Regionen und Zeilen) angezeigt wird (Abb. 21). Hier können - was durchaus wichtig sein kann - Regionen und Zeilen miteinander ausgetauscht werden.
- Aktionen mit Regionen:
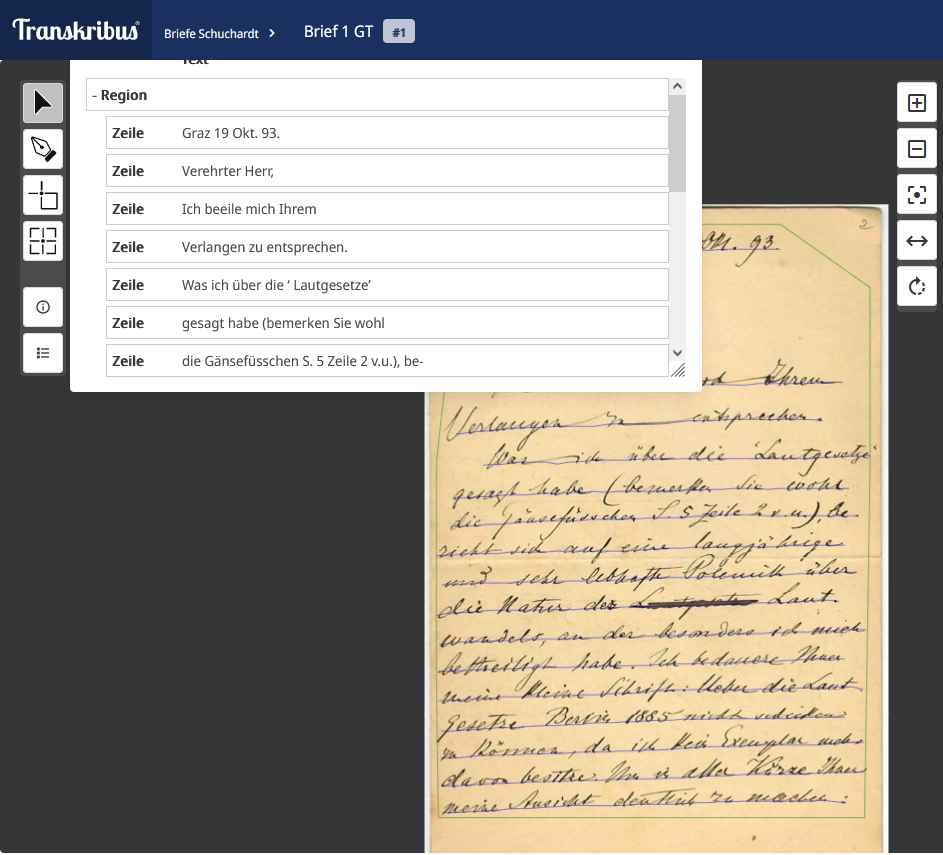
8. Anreicherung von Struktur und Inhalt der Texte über den Editor
- Auszeichnen von Text
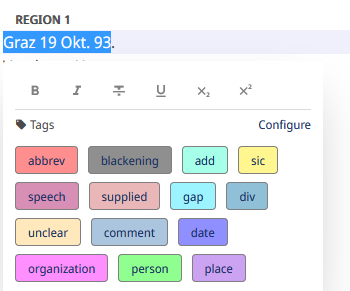
- Markieren wir im Texteditor eine Textpassage, öffnet sich ein Popup-Fenster (Abb. 22), das Möglichkeiten zur Textauszeichnung anbietet.
- Format: fett, kursiv, durchgestrichen, unterstrichen, hochgestellt und tiefgestellt
- Tagging: Textpassagen können mittels der von Transkribus vorkonfigurierten oder eigenen Tags ausgezeichnet werden. Über die “Configure”-Schaltfläche im Popup kann gesteuert werden, welche Tags zur Auswahl angezeigt werden, wenn eine Textpassage markiert wird.
- Markieren wir im Texteditor eine Textpassage, öffnet sich ein Popup-Fenster (Abb. 22), das Möglichkeiten zur Textauszeichnung anbietet.
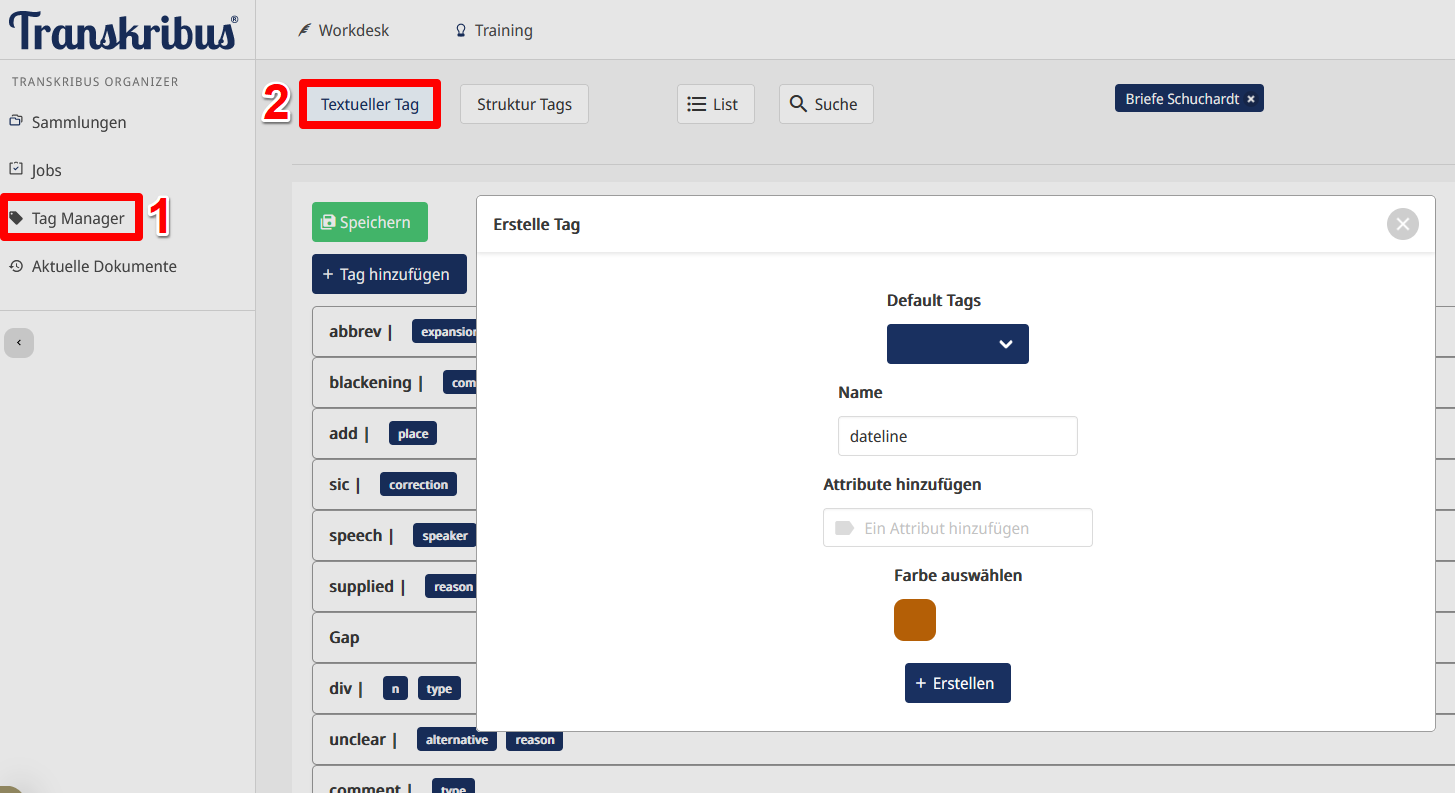
- Anlegen eigener Texttags: Da wir eigene und TEI-konforme Tags verwenden wollen, müssen wir diese zuerst anlegen. Dazu navigieren wir zurück in unsere Sammlung und klicken links im Transkribus Organizer auf “Tag Manager” (Tags werden in Transkribus immer für eine Sammlung konfiguriert). Da unsere Briefe über Datumszeilen verfügen, das TEI-konforme Tag “dateline” aber noch nicht in Transkribus vorkonfiguriert ist, erstellen wir es. Optional könnten wir dem Tag auch ein oder mehrere Attribute hinzufügen (Abb. 23).
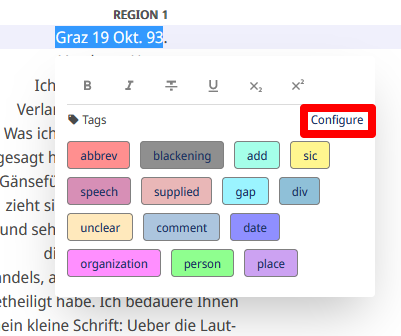
- Auszeichnen unsere Transkription: Wir wollen nun den Text unseres ersten Briefes annotieren und die Funktionalitäten des Editors testen. Da es sich bei Transkribus Lite um keinen vollwertigen Ersatz für ein TEI-konformes Annotationswerkzeug handelt, werden wir nicht versuchen, eine bestmögliche Annotation anzufertigen, sondern lediglich einige der Möglichkeiten erproben. Dazu navigieren wir in der Sammlungsübersicht in das Dokument “Brief 1” und öffnen die erste Seite des Briefes. Wir wollen die Datumszeile unseres Briefes auszeichnen und markieren sie, nun öffnet sich ein Popup. Damit wir unser neues Tag auch auswählen können, müssen wir es zuerst über “Configure” sichtbar schalten (Abb. 24).
- Nachdem wir das erledigt haben, können wir die Datumszeilen taggen. Tags können auch verschachtelt werden. Wir wählen die Datumsangabe innerhalb der Datumszeile an und weisen ihr das Tag “date” zu und weisen dem Attribut “when” das normalisierte Datum “1893-10-13” zu (Abb. 25).
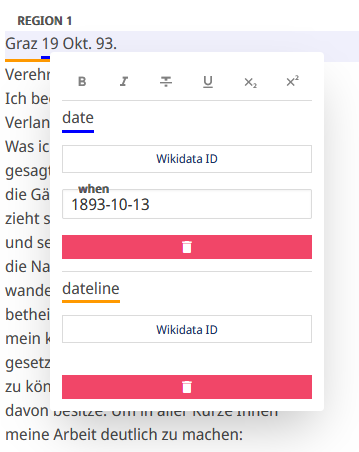
- Nun legen wir noch die neuen Tags “opener” an “salute” und taggen damit die Datumszeile und die Grußformel. In unserem Fall umfasst der Opener zwei Zeilen (abb. 26, grüne Linie) und enthält eben ein dateline-Element (abb. 26, orange Linie) und ein salute-Element (Abb. 26, gelbe Linie).

- Es zeigt sich allerdings gleich, dass die Annotationsmöglichkeiten von Transkribus stark eingeschränkt sind. Während der Editor durch die zwei Zeilen umspannende grüne Linie suggeriert, dass die gesamten zwei Zeilen von einem Tag umgeben würden, zeigt sich im TEI/XML-Export, dass dies leider nicht der Fall ist. Stattdessen wird jede der beiden Zeilen von einem seperaten opener-Tag umschlossen, das zudem auch in der ersten Zeile innerhalb des dateline-Tags platziert wird. Es gibt in Transkribus keine Möglichkeit festzulegen, wobei es sich um das innere und wobei es sich um das äußere Tag handelt.
<lb facs="#facs_1_tr_4_tl_1" n="N001"/><dateline><opener>Graz <date when="1893-10-19">19 Okt. 93.</date></opener></dateline>
<lb facs="#facs_1_tr_1_tl_1" n="N002"/><opener><salute>Verehrter Herr,</salute></opener>
- Wir verzichten daher auf eine Annotation des Openers und taggen lediglich Textpassagen, die nicht mehrere Zeilen umfassen. Dabei handelt es sich um die sich weiter unten befindliche, zweite Datumsangabe auf der ersten Seite des Briefs. Auf den nächsten beiden Seiten zeichnen wir mit den Formatoptionen die unterstrichenen und höhergestellten Wörter aus, bei der letzten Seite stoßen wir wieder auf dasselbe Problem: Sowohl salute als auch der closer würden mehr als eine Zeile umspannen. Wir zeichnen diese also nicht aus, sondern legen lediglich ein “name”-Tag an, um den Namen des Briefschreibers taggen (Abb. 26).
9. Export der Dokumente
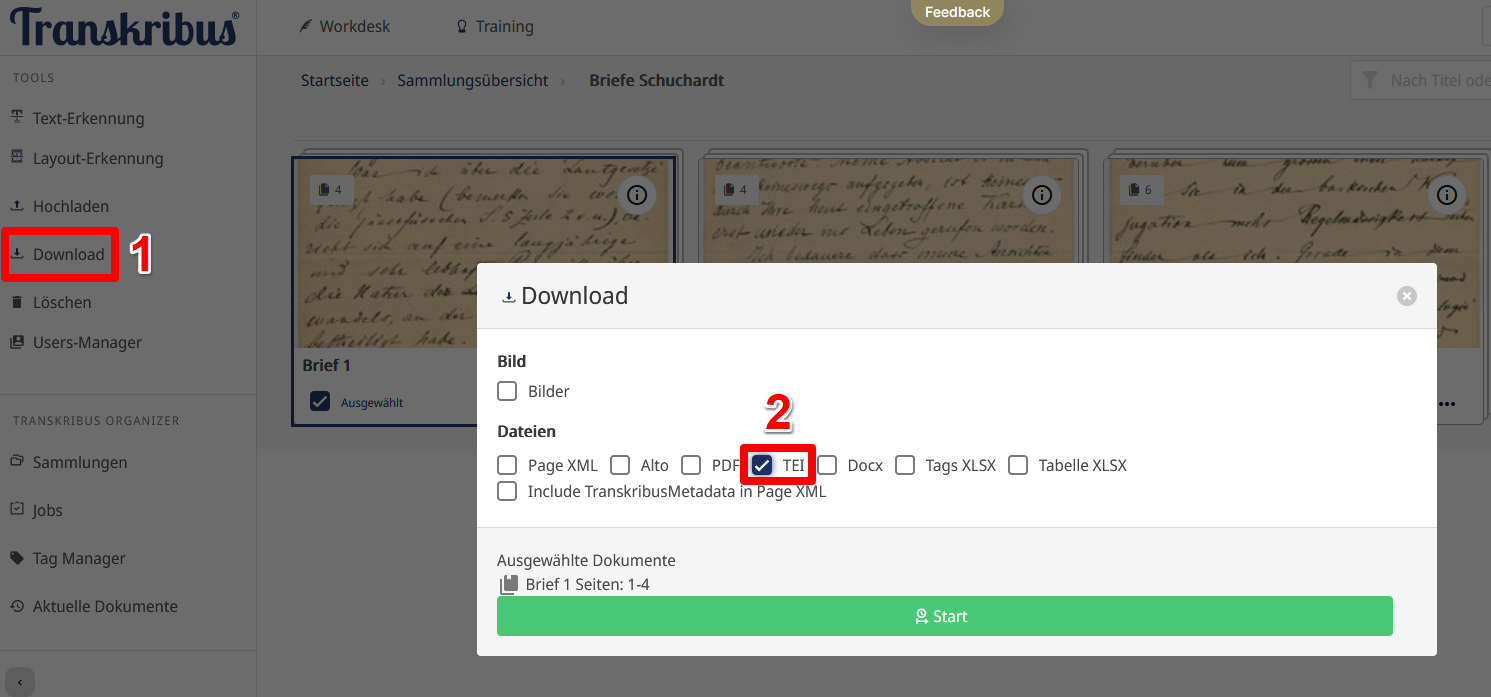
- Downloadfunktion in der Sammlungsübersicht: Da wir unsere Daten noch weiter annotieren und anreichern wollen, ist es für uns am sinnvollsten, sie als TEI-XML zu exportieren. Innerhalb unserer Sammlung können wir die Dokumente selektieren, die wir herunterladen wollen. Wir selektieren unseren bereits testweise annotierten ersten Brief und klicken auf “Download”. Im Popup wählen wir bei den unterschiedlichen Exportformaten lediglich “TEI” aus (Abb. 27). Wir bekommen nun auf unsere E-Mail-Adresse einen Downloadlink zugeschickt, mit dem wir eine ZIP-Datei herunterladen können.
Überprüfung und Validierung der TEI-Datei:
Kontakte
Unternehmensgröße: Mehr als 30 Mitarbeiter:innen (Stand Juni 2023)
Weblink: https://lite.transkribus.eu/
Mailkontakt: Kontaktformular bzw. Allgemeine Kontakt-E-Mail-Adresse: info@readcoop.eu
Ressourcen
Dokumentation
- Hilfecenter mit Schritt-für-Schritt-Anleitungen: https://help.transkribus.com/
- Dokumentation für Entwickler:innen: https://readcoop.eu/transkribus/docu/
Tutorials
YouTube-Channel von Transkribus
Video-Tutorials
Projekte
Siehe Slides Workshop vom 23./24. Februar
Literatur
- Alvermann, D., & Gut, P. (2021). Transkribus im Archiv – Ein polnisch-deutsches Projekt zur Handschriftentexterkennung an historischen Dokumenten. Archeion, 122, 129–153. https://doi.org/10.4467/26581264ARC.21.00614486
- Chambat, A., & Taaffe, C. (2022). ABBYY FineReader and Transkribus as philological tools: Digitizing multilingual and dialphabetic ancient medical dictionaries (16th–18th centuries). https://hal-cyu.archives-ouvertes.fr/hal-03852198
- Colutto, S., Kahle, P., Guenter, H., & Muehlberger, G. (2019). Transkribus. A Platform for Automated Text Recognition and Searching of Historical Documents. 2019 15th International Conference on eScience (eScience), 463–466. https://doi.org/10.1109/eScience.2019.00060
- Jakob Böhm, A. G. (2019, Oktober 11). Transkribus auf dem Prüfstand (II) [Billet]. Mittelalter. https://mittelalter.hypotheses.org/22600
- Kahle, P., Colutto, S., Hackl, G., & Mühlberger, G. (2017). Transkribus—A Service Platform for Transcription, Recognition and Retrieval of Historical Documents. 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), 04, 19–24. https://doi.org/10.1109/ICDAR.2017.307
- Kokaze, A. (2022). Using Transkribus to Transcribe Eighteenth-Century French Historical Manuscripts. Historical Studies of the Western World, 1, 9. https://doi.org/10.57271/hsww.1.0_9
- Massot, M.-L., Sforzini, A., & Ventresque, V. (2019). Transcribing Foucault’s handwriting with Transkribus. Journal of Data Mining and Digital Humanities, Atelier Digit_Hum. https://doi.org/10.46298/jdmdh.5043
- Milioni, N. (2020). Automatic Transcription of Historical Documents: Transkribus as a Tool for Libraries, Archives and Scholars. https://urn.kb.se/resolve?urn=urn:nbn:se:uu:diva-412565
- Muehlberger, G., Seaward, L., Terras, M., Ares Oliveira, S., Bosch, V., Bryan, M., Colutto, S., Déjean, H., Diem, M., Fiel, S., Gatos, B., Greinoecker, A., Grüning, T., Hackl, G., Haukkovaara, V., Heyer, G., * Hirvonen, L., Hodel, T., Jokinen, M., … Zagoris, K. (2019). Transforming scholarship in the archives through handwritten text recognition: Transkribus as a case study. Journal of Documentation, 75(5), 954–976. https://doi.org/10.1108/JD-07-2018-0114
- Nockels, J., Gooding, P., Ames, S., & Terras, M. (2022). Understanding the application of handwritten text recognition technology in heritage contexts: A systematic review of Transkribus in published research. Archival Science, 22(3), 367–392. https://doi.org/10.1007/s10502-022-09397-0
- Ó Raghallaigh, B., Palandri, A., & Mac Cárthaigh, C. (2022). Handwritten Text Recognition (HTR) for Irish-Language Folklore. Proceedings of the 4th Celtic Language Technology Workshop within LREC2022, 121–126. https://aclanthology.org/2022.cltw-1.17
- Perdiki, E. (2022). Transkribus: Reviewing HTR training on (Greek) manuscripts. 15. https://doi.org/10.18716/ride.a.15.6
- Perdiki, E. (2023). Preparing Big Manuscript Data for auto Collation with minimal HTR training. https://hal.science/hal-03880102
- Polomac, V. (2022). Serbian Early Printed Books from Venice: Creating Models for Automatic Text Recognition Using Transkribus. Scripta & e-Scripta, 22, 11–29.
- Polomac, V., & Lutovac Kaznovac, T. (2021). Automatic Recognition of Serbian Medieval Manuscripts by Applying the Transkribus Software Platform: Current Situation and Future Perspectives. Зборник Матице српске за филологију и лингвистику, 64(2), 7–26. https://doi.org/10.18485/ms_zmsfil.2021.64.2.1
- Prell, M. (2018). Erfahrungs- und Ergebnisbericht zum Transkribus-Projekt: »ps: Ich bitt noch mahl umb ver gebung meines confusen und üblen schreibens wegen«. Frühneuzeitliche Briefe als Herausforderung automatisierter Handschriftenerkennung. https://www.academia.edu/36792560/ERFAHRUNGS_UND_ERGEBNISBERICHT_ZUM_TRANSKRIBUS_PROJEKT
- Rabus, A. (o. J.). Training generic models for Handwritten Text Recognition using Transkribus: Opportunities and pitfalls. To appear in Proceedings of the Dark Archives Conference, Oxford 2019. Abgerufen 22. Juni 2023, von https://www.academia.edu/49356690/Training_generic_models_for_Handwritten_Text_Recognition_using_Transkribus_Opportunities_and_pitfalls
- Rabus, A. (2019). Recognizing Handwritten Text in Slavic Manuscripts: A Neural-Network Approach Using Transkribus. Scripta & e-Scripta, 19, 9–32.
- Schlagdenhauffen, R. (2020). Optical Recognition Assisted Transcription with Transkribus: The Experiment concerning Eugène Wilhelm’s Personal Diary (1885-1951). Journal of Data Mining & Digital Humanities, Atelier Digit_Hum(Digital humanities in…), 6249. https://doi.org/10.46298/jdmdh.6249
- Serif, I. (2019). Ein Wolpertinger für die Vormoderne: Zu Nutzungs- und Forschungsmöglichkeiten von Transkribus bei der Arbeit mit mittelalterlichen und frühneuzeitlichen Handschriften und Drucken. In Mittelalter. Interdisziplinäre Forschung und Rezeptionsgeschichte (Bd. 2, S. 125–166) [Working Paper]. Mittelalter. Interdisziplinäre Forschung und Rezeptionsgeschichte. https://edoc.unibas.ch/70997/
- Spina, S. (2022). The Biscari Archive. A case study of the application of Transkribus tool (arXiv:2210.14498). arXiv. https://doi.org/10.48550/arXiv.2210.14498
- Thompson, W. (2021). Using Handwritten Text Recognition (HTR) Tools to Transcribe Historical Multilingual Lexica. Scripta & e-Scripta, 21, 217–231.
- Vukčević, M. M. (2020). Turns of the centuries. The Transkribus automated tool for recognition, transcription and translation of handwritten historical documents: A German-Serbian case study. Babel. Revue Internationale de La Traduction / International Journal of Translation, 66(2), 294–310. https://doi.org/10.1075/babel.00159.vuk
Factsheet zum Tooldoc
| System | |
| Scope des Tools | Primär KI-gestützte Layout- und Texterkennung von gedruckten und handgeschriebenen Texten, Training von Layout- und Texterkennungsmodellen. Annotationen mit Einschränkungen möglich |
| Softwareumgebung/Softwaretyp (Remotesystem im Browser / Lokaler Client) | Browser-Anwendung/web-basiert |
| Unterstützte Plattformen | Windows, Linux, Mac |
| Geräte | Desktop |
| Einbindung anderer Systeme (Interoperabilität) | ❌(Private FTP, IIIF Manifest und DFG Viewer METS derzeit nur bei Transkribus eXpert) |
| Accountsystem | ✅ |
| Kostenmodell (Kostenübersicht/Open Source) | Layouterkennung und Training von Layout- und Texterkennungsmodellen, Upload, manuelle Transkription, Anreicherung und Download der Daten kostenfrei Creditsystem für automatische Texterkennung (1 Credit = 1 handgeschriebene Seite oder 1 Credit = 6 gedruckte Seiten) 500 Credits bei Registrierung kostenlos (= 500 handgeschriebene oder 3000 gedruckte Seiten) |
| Anforderungen & Methoden | |
| Erforderte Code Literacy | ❌ |
| Interface-Sprachen (ISO 639-1) | de, en, es, et, fi, fr, it, nl, pl, pt, sl, sv |
| Unterstützte Zeichenkodierung | UTF-8 |
| Inkludierte Datenkonvertierung (Im Preprocessing mögliche Anpassung der Daten an für die Software erforderliches Format ) | ❌ |
| Abhängigkeit von anderer Software (Falls ja, wird diese Software automatisch mitinstalliert?) | ❌ |
| Erforderliche Plug-Ins (bei web-basierten Anwendungen) | ❌ |
| Dokumentation und Support | |
| Wartung und ständige Erweiterung | ✅ |
| Einbindung der Community | ✅ Privatpersonen und Institutionen können Mitglied der Genossenschaft READ-COOP SCE und damit Miteigentümer des Unternehmens werden (Vorteile: Rabatte, 500 freie Credits pro Jahr, Erhalt privilegierter Informationen, Stimmrecht u. a.) |
| Dokumentation | ✅ |
| Dokumentationssprache | HelpCenter (Englisch, Deutsch, Italienisch), How-to-Guides (Englisch), Glossar (Englisch), FAQ (Englisch, Deutsch, Italienisch) |
| Dokumentationsformat | HTML |
| Dokumentationsabschnitte | Ausführliche Dokumentation im HelpCenter (Erste Schritte, Texterkennung, Layouterkennung, Händisch transkribieren, Modelltraining, Tagging, Suchen, Verwalten, Herunterladen), How-to-Guides, Glossar, FAQ |
| Verfügbarkeit von Tutorials | ✅ Schritt-für-Schritt-Anleitungen (HelpCenter, How-to-Guides), instruktive mehrsprachige Einführungswebinare sowie weitere Videos auf YouTube verfügbar |
| Aktiver Support/Community (Forum, Slack, Issue Tracker etc.) | ✅ Kontaktformular, aktive, aber nicht von Transkribus administrierte Facebook-Gruppe |
| Nutzbarkeit & Nachhaltigkeit | |
| Installationsablauf | keine Installation nötig |
| Test (Gibt es ein Test Suite, um zu überprüfen, ob die Installation erfolgreich war?) | [nicht anwendbar] |
| Lizenz, unter der das Tool veröffentlicht wurde | Proprietäre Software |
| Registrierung in einem Repository | ❌ |
| Möglichkeit, zur Software-Entwicklung beizutragen | ❌ |
| Benutzerinteraktion & Benutzeroberfläche | |
| Benutzerprofil (Erwartete Nutzer:innen) | Primär GeWi-Forschungsinstitutionen, Forschende und Bibliotheken (Smart Search) als Tool-Nutzende |
| Benutzerinteraktion (erwartete Nutzung) | Anlegen von Sammlungen und Dokumenten, Hochladen von Dateien, KI-gestützte Layout- und Texterkennung, Training von Layout- und Texterkennungsmodellen, Anreicherung von Texten |
| Benutzeroberfläche | Webbasiertes GUI |
| Visualisierungen (Analyse-, Input-, Outputkonfigurationen) | ❌ |
| Benutzerverwaltung | |
| Personenverwaltung | ✅Hinzufügen/Einschränkung von Mitarbeitenden möglich |
| Interne Kommunikationsmöglichkeiten (z. B. Annotationsrichtlinien, Kommentarfunktionen …) | ❌ |
| Daten- und Toolverwaltung | |
| Zentrale/dezentrale Verwaltungsmöglichkeit | ✅ Mehrere Sammlungseigentümer:innen möglich möglich |
| Versionskontrolle | ✅ Bei den einzelnen transkribierten Seiten |
| Projektspezifische Einstellungen (eigene Metadaten, Tags anlegbar etc.) | ✅ |
| API | ✅ MetagraphoAPI |
| Möglichkeit des simultanen Arbeitens | ✅ Nicht simultan an einzelnen Seiten, aber Dokumenten und Sammlungen |
| Datenupload | |
| Unterstützte Dateiformate | Bilder (JPEG, PNG) oder PDFs |
| Informationen zur Datensicherheit | Alle hochgeladenen Dokumente sind standardmäßig privat. Die Daten werden auf Servern in Innsbruck (Österreich) in DSGVO-konformer Weise gespeichert und können gemäß den Terms & Conditions der READ-COOP SCE verarbeitet werden |
| Zugänglichkeit von verschiedenen Standorten/Geräten | ✅ |
| Einschränkungen hinsichtlich der Datenmenge | ❌ |
| Verlustfreier Upload von bereits bearbeiteten Dokumenten | [nicht anwendbar, da noch keine Annotation stattgefunden hat] |
| Unterstützung von IIIF-Import | ❌ (derzeit IIIF Manifest nur in Transkribus eXpert unterstützt) |
| Datenbearbeitung (Transkriptionstool) | |
| Komplexitätsgrad beim Mark-Up (z.B. Verfügbarkeit von Buttons, Drag&Drop-Funktion) | Strukturtags (Faksimilie) und Texttags, Formatauszeichnung (fett, kursiv usw.) |
| Standardeinstellungen entsprechend bestimmten Standards für Digitale Editionen | ❌ |
| Anpassungsmöglichkeit und Validierung entsprechend projektspezifischen Konventionen/Schemata | ✅ Tags an TEI anpassbar, allerdings keine Validierungsmöglichkeit |
| Definition eigener/projektspezifischer Tags | ✅ |
| Metadaten-Anreicherung | ✅ (Sammlungs- und Dokumentmetadaten) |
| Layoutmöglichkeiten (z.B. Tabellendarstellung, Spalten wie in Zeitschriften …) | ❌ |
| Eigene Indexierung | ❌ |
| Möglichkeit von Textvergleich bzw. Arbeit an Variantenapparat | ❌ |
| Ansichtsmöglichkeiten (z. B. Bearbeitungsansicht, Vorschau, Synopsen-Ansicht …) | Bild-Texteditor-Synopse |
| Verlinkung von Entitäten, NER | ❌ |
| Datenexport | |
| Unterstützte Dateiformate | PAGE XML, ALTO XML, TEI XML, PDF (Bild- und Transkriptionslayer), Docx, Tags XLSX, Table XLSX |
| Datenverlust (nicht vollständiger Erhalt von Annotationen, die bereits vor Verwendung des Tools gemacht wurden) | [nicht anwendbar] |
| Validierungsmöglichkeit für TEI-XML vor Export | ❌ |
| Datenaufbewahrung nach Export | Sammlungen, in denen 120 Tage keine Aktivität stattfand, werden archiviert und an die Eigentümer:innen wird ein Mail versandt. Finden dann innerhalb der nächsten 21 Tag keine Aktivitäten statt, werden die Sammlungen gelöscht |