
ediarum.WEB
Allgemeine Beschreibung
ediarum.WEB ist ein sich in Entwicklung befindliches Modul von ediarum, einem Open-Source-Softwareprojekt der TELOTA-Initiative der Berlin-Brandenburgischen Akademie der Wissenschaften. Bei ediarum.WEB handelt es sich um eine Bibliothek für die eXist-db, die es zum Ziel hat, das schnelle und einfache Publizieren von (TEI-)XML-Dateien zu ermöglichen.
Anwendungsbereiche
- Webpublikation von (TEI-)XML-Daten
Funktionsübersicht
- Erstellung von digitalen Editionen
- Einfaches Anlegen von sogenannten Objekten (z. B. Briefen, Personen, Orte und Organisationen im Falle unserer Briefedition) und Beziehungen zwischen den Objekten (z. B. Person A als Absender von Brief B oder Nennung von Ort X in Brief Y)
- Anlegen von Filtern bei Objekten (z. B. nach Jahreszahlen bei Briefen oder nach Alphabet bei Personen) möglich
- Transformation der Daten bei Objekten durch das Einbinden XSLT-Stylesheets möglich
- Referenzierung von Teilen der Objekte (z. B. Seiten von Briefen, eine Verschachtelung ist möglich, z. B. Seiten und Zeilen)
- Einbindung einer Suche möglich
- API-Einbindung
Voraussetzungen
Jedes Tool kann einerseits bestimmte Vorkenntnisse der Benutzer:innen voraussetzen und andererseits auch hinsichtlich der Software-Umgebung gewisse Anforderungen stellen.
Erforderliche Kenntnisse
- TEI-XML
- XPath
- XQuery
- XSLT
- HTML/CSS-Grundkenntnisse
- JavaScript
Benötigte Software
- eXist-db
- Docker Desktop (für eine einfachere Installation von eXist-db)
Tool-Kompatibilität
| IIIF | Transkribus | FromThePage | FairCopy | ediarum | OpenRefine | ba[sic?] | TEI Publisher | |
| ediarum.WEB | ❌ | ❌ | ❌ | 🦄 | ✅ | ❌ | ❌ | ❌ |
Kostenübersicht
- ediarum.WEB & eXist-db:
- kostenlos
Möglichkeiten & Grenzen
Da jedes Projekt unterschiedliche Anforderungen mit sich bringt, sollen nachfolgend mögliche Vor- und Nachteile des getesteten Tools dargestellt werden.
Stärken
- Vorkonfiguriertes Basislayout, das adaptiert werden kann
- Basale digitale Editionen mit typischen Funktionalitäten (z. B. Filter bei Objekten wie Personen (z. B. alphabetisch) und Texten (z. B. nach Jahreszahl) schnell und relativ einfach umsetzbar
- Rückgriff auf eine große Menge an vordefinierten XQuery-Funktionen möglich, um eine Vielzahl an potentiell gewünschten Funktionalitäten umzusetzen
- Kontinuierliche Weiterentwicklung (letztes Release im Mai 2023)
- Hilfsbereiter und reaktionsschneller Support
Herausforderungen & Probleme
- Höhere Einstiegsvoraussetzungen:
- Zumindest Grundvertrautheit mit eXist-db erforderlich, idealerweise fortgeschrittene Kenntnisse
- DH-Enwickler:in für die Umsetzung komplexerer digitaler Editionen erforderlich (z. B. fortgeschrittene XQuery-Kenntnisse für das Verständnis und die Anwendung der Funktionen, Webdesign-Kenntnisse, XSLT-Kenntnisse usw.)
- Abhängigkeit von eXist-db
Einrichtung & Erste Schritte
Anhand einesBeispielprojekts, in dem mit handgeschriebenen Briefen des Linguisten Hugo Schuchardt (1842-1927) aus dem 19. Jahrhundert bzw. 20. Jahrhundert gearbeitet wird, soll nachfolgend ein möglicher Arbeitsablauf mit dem Publikationstool ediarum.WEB beschrieben werden. In einem ersten Schritt wurden die handgeschriebenen Briefe bereits mittels des OCR/HTR-Tools Transkribus Lite transkribiert. Danach wurde der TEI/XML-Export in den TEI/XML-Editor FairCopy ingestiert und tiefergehend annotiert, wobei Named Entities (Personen, Orte und Organisationen) ausgezeichnet wurden. Diese Named Entities wurden im Zuge des ersten Teils der Transition aus den Briefen extrahiert und dann mittels des Normalisierungstools ba[sic?] um Normdaten ergänzt (Links auf GND- und GeoNames-Einträge). Danach wurden diese erhobenen Informationen im zweiten Teil der Transition wieder mit den Briefen zusammengeführt. In der letzten, hier dokumentierten Phase des Beispielprojekts sollen nun die Möglichkeiten der Publikation der Briefe mittels des Tools ediarum.WEB erprobt werden.
1. Installation einzelner Komponenten
- Installation der XML-Datenbank eXist-db: Da es sich bei ediarum.WEB um eine Bibliothek für eXist-db handelt, müssen wir diese Datenbank zunächst installieren. Wir entscheiden uns für die Installation via Docker Desktop, die hier erläutert wird.
- Installation von ediarum.WEB in eXist-db: Im nächsten Schritt muss nun ediarum-WEB in eXist-db eingerichtet werden.
-
Dafür laden wir aus dem ediarum.WEB-GitHub-Repository die aktuellste Version (2.1.1) von ediarum.WEB als XAR-Datei herunter.

Download von ediarum.WEB via GitHub -
Nach Starten von eXist-db und Einloggen als Admin kann die XAR-Datei über den Package Manager hochgeladen werden:
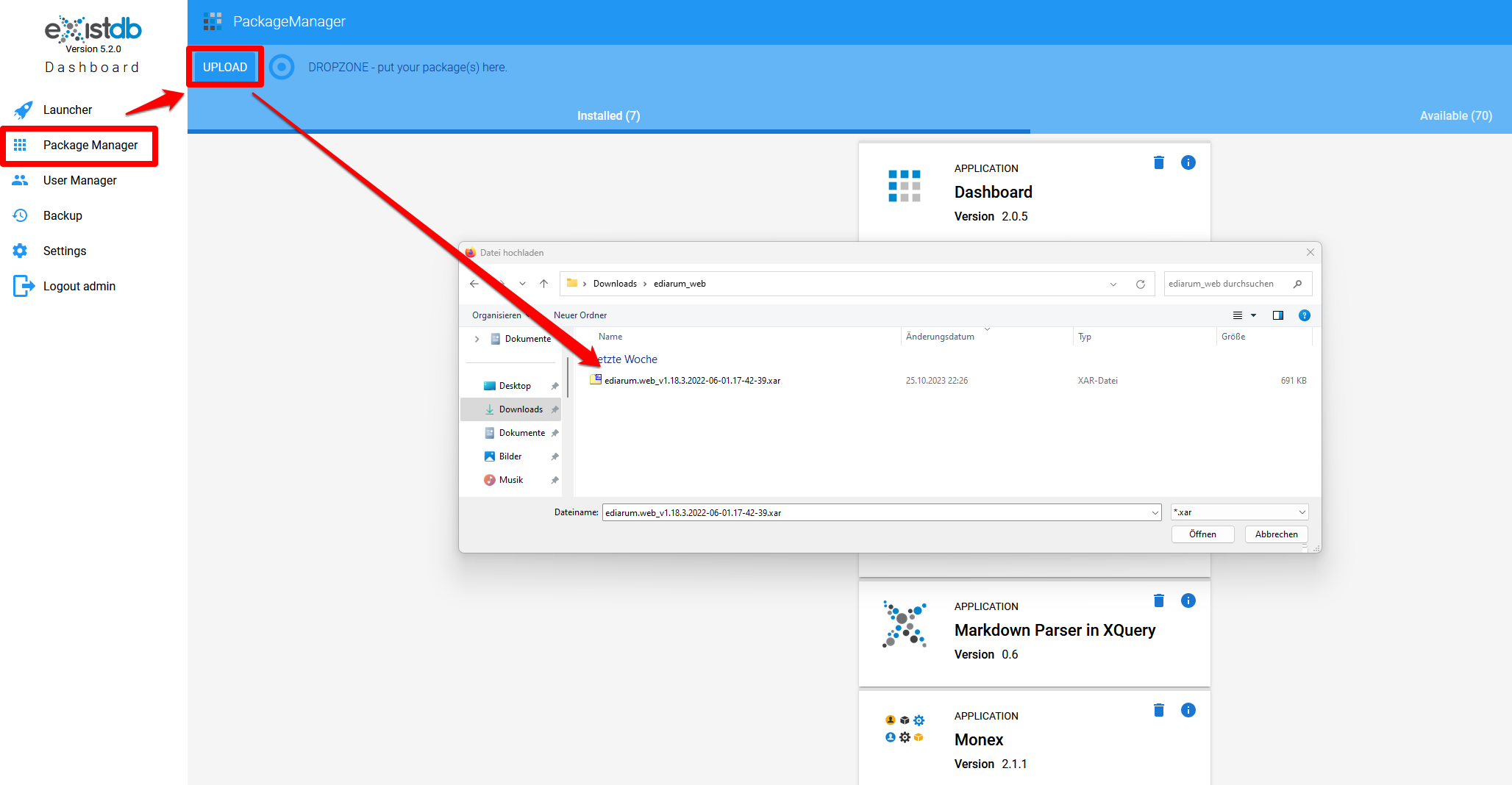
Upload von ediarum.WEB in die eXist-db -
ediarum.WEB wird nicht im Package Manager als App angezeigt, betätigt man aber die Launcher-Schaltfläche und startet dann die eXide-IDE, findet man ediarum.WEB im Ordner “apps” vor.
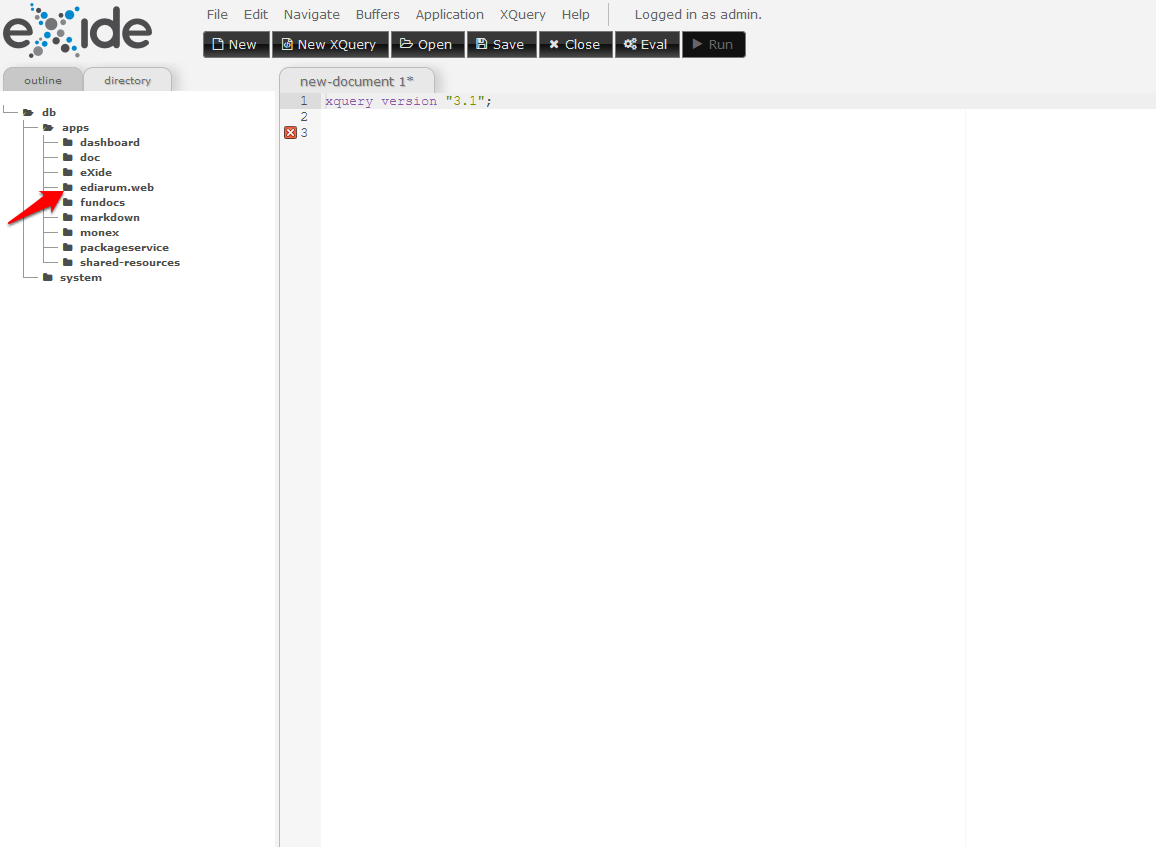
ediarum.WEB in der eXide-IDE
-
2. Einrichtung des Projekts
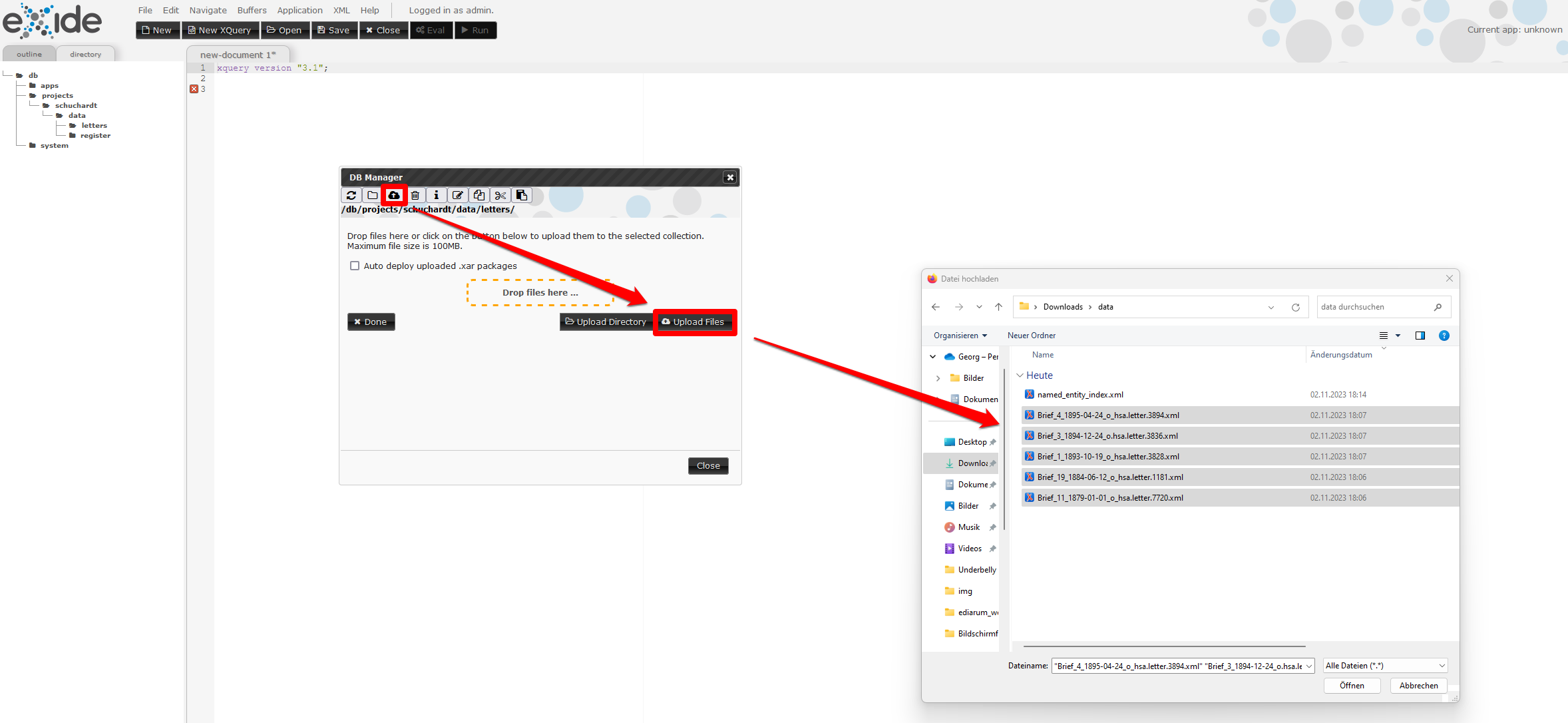
- Zunächst müssen wir unsere XML-Dateien, die Briefe Hugo Schuchardts und das Named-Entity-Register, in eXist-db hochladen. Dazu öffnen wir eXide, wählen im Reiter “File” und daraus “Manage” aus, woraufhin sich der Dateimanager öffnet.
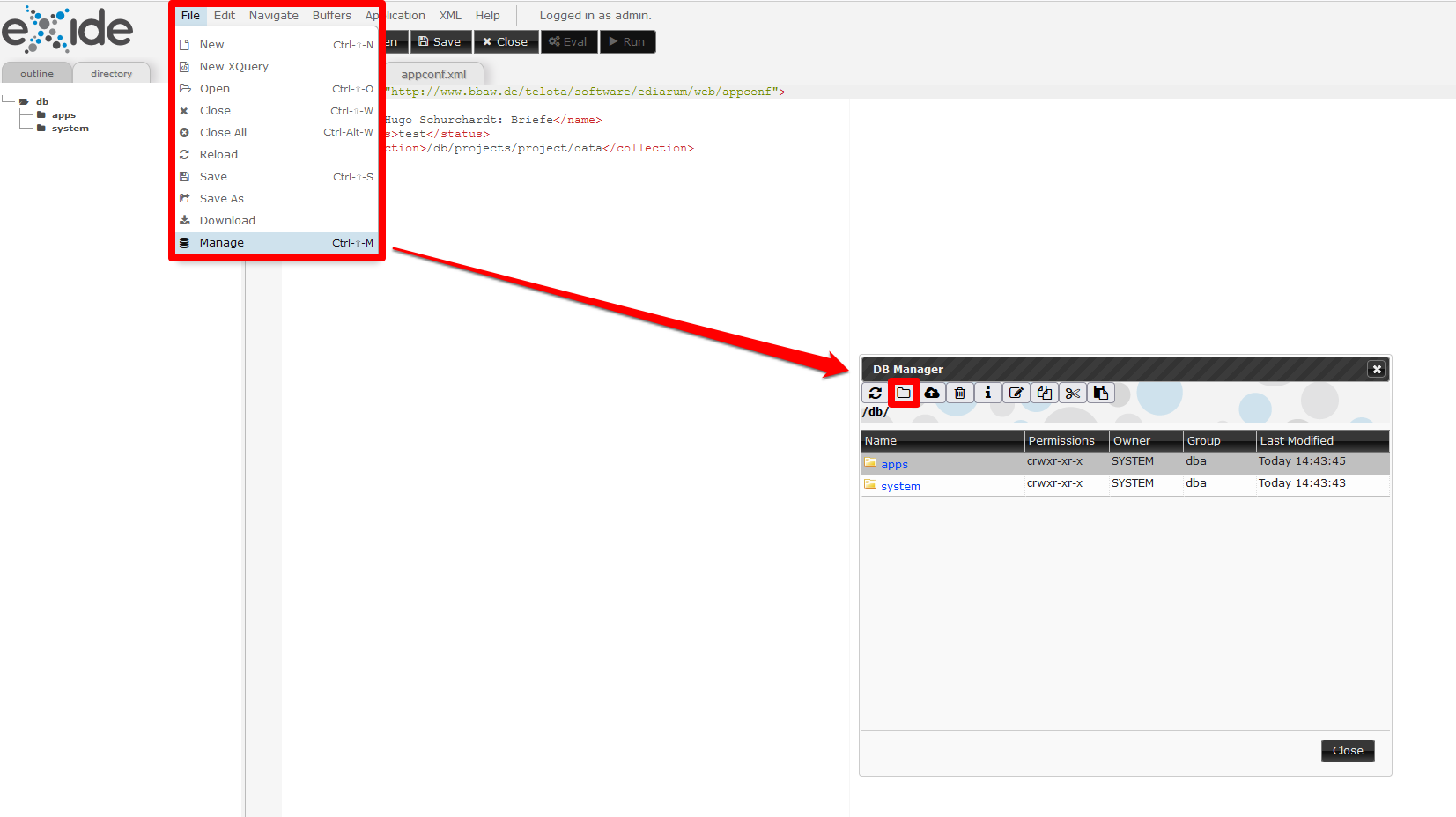
Auf der Ebene der Ordner “apps” und “system” legen wir einen Ordner namens “projects” an und in diesem erzeugen wir folgende verschachtelte Struktur:
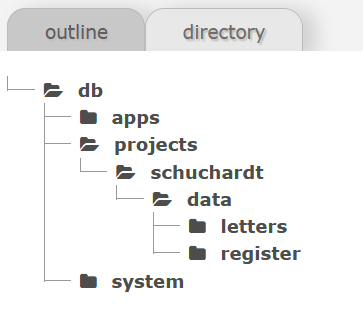
Danach navigieren wir in den Ordner “letters”, klicken auf das Wolkensymbol und laden die fünf Briefe Hugo Schuchardts hoch. Ist dies erledigt, kehren wir mittels Klick auf “done” zur Navigationsansicht zurück und laden in gleicher Weise das Named-Entity-Register in den Ordner “register” hoch.
3. Bearbeitung der Dokumente
-
Anpassen des Titels der Indexsseite: Zuerst wollen wir den Titel unseres Projekts abändern und navigieren dazu über eXide in den Ordner “templates” und öffnen die Datei “page.html”. Dort ändern wir die beiden Vorkommnisse von “Workshop” auf “Hugo Schuchardt: Briefe” ab, speichern die Datei und laden dann die Indexseite neu.
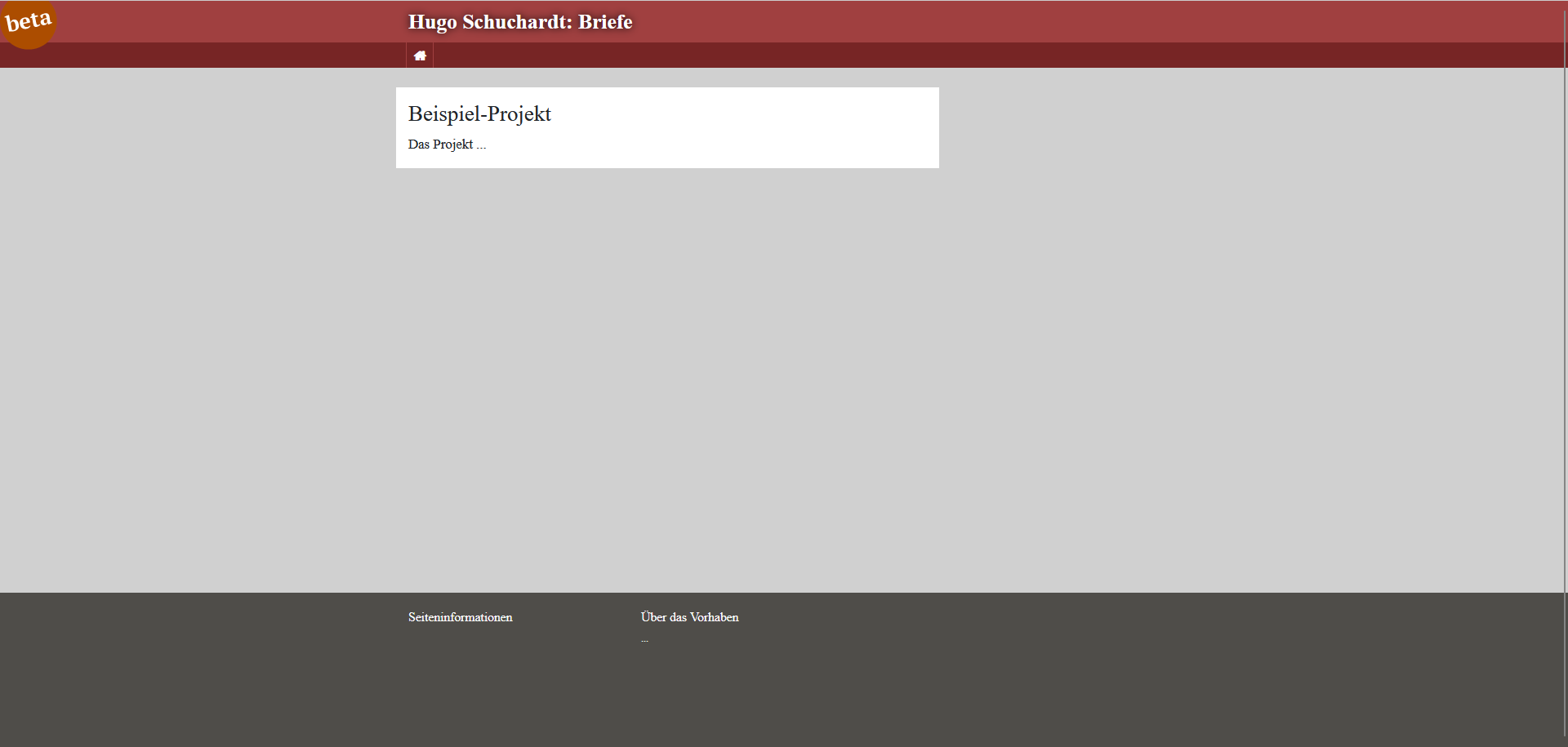
Die neue Indexsseite Den Footer und die Projektbeschreibung passen wir zunächst nicht an, beiden werden wir uns später zuwenden.
-
Bearbeiten der Projektinformationen: Als nächstes öffnen wir die Datei
appconf.xml, um die Projektinformationen zu bearbeiten.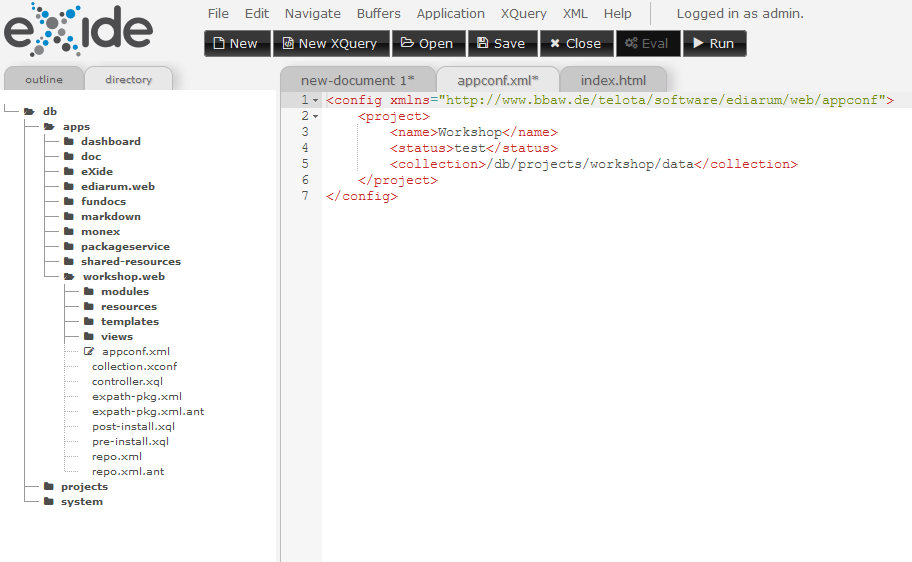
Die Datei appconf.xml Wir ändern die dort im
<project>-Element vorhandenen Daten wie folgt ab:<config xmlns="http://www.bbaw.de/telota/software/ediarum/web/appconf"> <project> <name>Hugo_Schuchardt_Briefe</name> <status>test</status> <collection>/db/projects/schuchardt/data</collection> </project> </config>Folgende Informationen werden hier mittels XML-Elemente festgelegt:
<name>: Hier wird der Projektname festgelegt, der Name dient auch als ID<status>: Hier wird der Status der Instanz festgelegt, unterschieden wird zwischen “test”, “internal” und “public”. Wir belassen hier den Status auf “test”<collection>: Hier wird mittels einem absolutem Pfad oder relativen Pfad zur “appconf.xml” festgelegt, wo die Projektdaten zu finden sind
-
Anlegen von Objekten und Beziehungen über die “appconf.xml”: Laut Dokumentation wird in der
appconf.xmlfestgelegt, wie die gewünschten Forschungsdaten aus dem XML-Datenbestand extrahiert werden. Es werden zwei Kategorien von Forschungsdaten definiert: Objekte (objects) und Beziehungen (relations). Als Objekte verschiedener Art können die unterschiedlichen atomaren Einheiten einer digitalen Edition verstanden werden. Eine Briefedition wie die unsrige kann z. B. folgende Objekttypen enthalten: Briefe, Personen, Orte, Schlüsselwörter usw. Zwischen den Objekten können Beziehungen hergestellt und definiert werden, z. B. zwischen einer Person und einem Brief (als Sender oder Empfänger) oder einer Person und einem Ort (z. B. als Geburtsort oder Wohnort). Neben Objekten und Beziehungen können auch Suchindizes definiert werden. Der allgemeine Aufbau derappconf.xmlsieht wie folgt aus:<config xmlns="http://www.bbaw.de/telota/software/ediarum/web/appconf"> <project> ... </project> <object> ...</object> <object> ...</object> ... <relation> ...</relation> <relation> ...</relation> ... <search> ...</search> <search> ...</search> ... </config>-
Anlegen eines Objekts für die Briefe: Um ein Objekt für die Briefe anzulegen, fügen wird folgendes XML-Snippet als Schwesternelement von
<project>ein:<object xml:id="briefe"> <name>Briefe</name> <collection>/letters</collection> <item> <namespace id="tei">http://www.tei-c.org/ns/1.0</namespace> <root>tei:TEI</root> <id>.//tei:publicationStmt/tei:idno[@type="PID"]</id> <label type="xpath">.//tei:titleStmt/tei:title[1]/normalize-space()</label> </item> </object>Folgend wird erläutert, wozu die Elemente dienen:
<object/@xml:id>: Hier wird die ID des Objekttyps festgelegt, sie wird zum Beispiel bei der Definition von Beziehungen benötigt<name>: Hier wird der Name des Objekttyps festgelegt, dieser kann im Frontend verwendet werden. Wir entscheiden uns für “Briefe”<collection>: Ein relativer Pfad zu dem im<project>angegebenen Pfad, in dem nach Objekten gesucht werden soll<namespace>: Hier können ein oder mehrere Namespaces angegeben werden, die dann in den in den nächsten Elementen angegebenen XPath-Ausdrücken verwendet werden. Das@idlegt das Namespace-Prefix fest.<root>: Hier wird das Wurzelement der Objekts angegeben, der verwendete Ausdruck muss ein qualified name sein. Wir geben hier das Wurzelelement der Briefe,<TEI>, an<id>: Hier muss ein XPath-Ausdruck angeführt werden, der angibt, wo die IDs der Objekte zu finden sind. In diesem Fall haben wir uns dazu entschieden, den<TEI>-Wurzelelementen der Briefe fortlaufende IDs zuzuweisen (“hsa.1” bis “hsa.5”), auf die wir hier zugreifen<label>: Hier muss ein XPath- oder XQuery-Ausdruck angegeben werden, mit dem das Label, also der Anzeigename, der Objekte festgelegt wird
Nach dem Speichern der
appconf.xmlund dem Neuladen der Indexseite finden wir die neue Schaltfläche “Briefe” vor. Wie sich zeigt, werden die Briefe in der Datenbank gezählt und als Liste ausgegeben.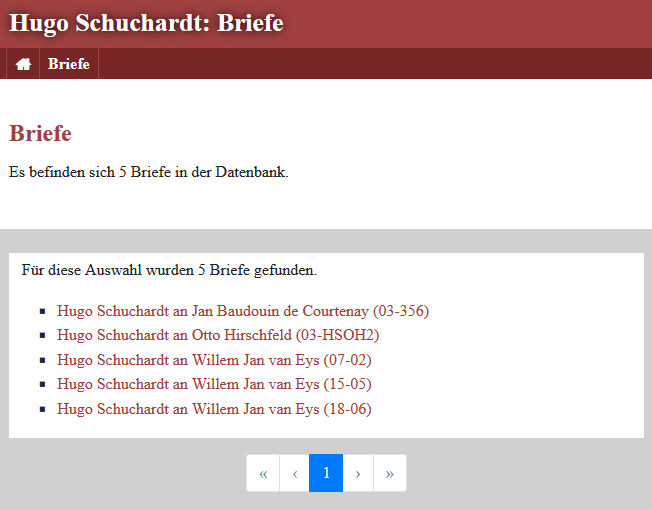
Die Briefe in der Datenbank -
Anlegen der Objekte für Personen, Orte und Organisationen: In gleicher Weise legen wir nun Objekte für die in unserem Named-Entity-Register verzeichneten Personen, Orte und Organisationen an. Zunächst passen wir den Pfad bei
<collection>an, sodass er auf den Ordner verweist, in dem die Registerdatei abgelegt ist. Das<root>-Element wird ebenfalls abgeändert und lautettei:person,tei:placeodertei:org. Ebenfalls muss noch der XPath-Ausdruck für das gewünschte Label angegeben werden, also z. B..//tei:persName/normalize-space()”Personen:
<object xml:id="personen"> <name>Personen</name> <collection>/register</collection> <item> <namespace id="tei">http://www.tei-c.org/ns/1.0</namespace> <root>tei:person</root> <id>./@xml:id</id> <label type="xpath">.//tei:persName/normalize-space()</label> </item> </object>Orte:
<object xml:id="orte"> <name>Orte</name> <collection>/register</collection> <item> <namespace id="tei">http://www.tei-c.org/ns/1.0</namespace> <root>tei:place</root> <id>./@xml:id</id> <label type="xpath">.//tei:placeName/normalize-space()</label> </item> </object>Organisationen:
<object xml:id="organisationen"> <name>Organisationen</name> <collection>/register</collection> <item> <namespace id="tei">http://www.tei-c.org/ns/1.0</namespace> <root>tei:org</root> <id>./@xml:id</id> <label type="xpath">.//tei:orgName/normalize-space()</label> </item> </object>Nach dem Speichern der
appconf.xmlund dem Neuladen der Indexseite finden wir nun Schaltflächen für Personen, Orte und Organisationen vor, wobei die Named Entities analog wie bei den Briefen aufgelistet werden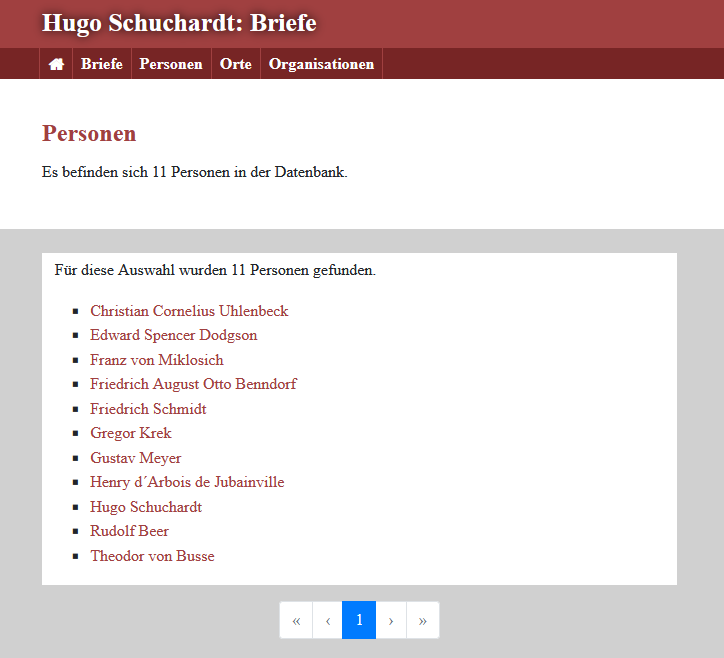
Die Indexseite mit den Schaltflächen für die Named Entities -
Anlegen von Properties (Filtern): Im nächsten Schritt wollen wir Filter anlegen, sodass wir die Briefe z. B. nach Jahren oder die Personen alphabetisch filtern können. Filter werden immer innerhalb von Objekten angelegt, wir fügen also innerhalb des Objekts “Briefe” folgenden XML-Block ein:
<filters> <filter xml:id="correspYear"> <name>Jahr</name> <type>union</type> <xpath>.//tei:correspAction//tei:date/@when/substring(.,1,4)</xpath> <label-function type="xquery">function($string){$string}</label-function> </filter> </filters>Die
appconf.xmlmit dem Filter nach Sendedatum der Briefe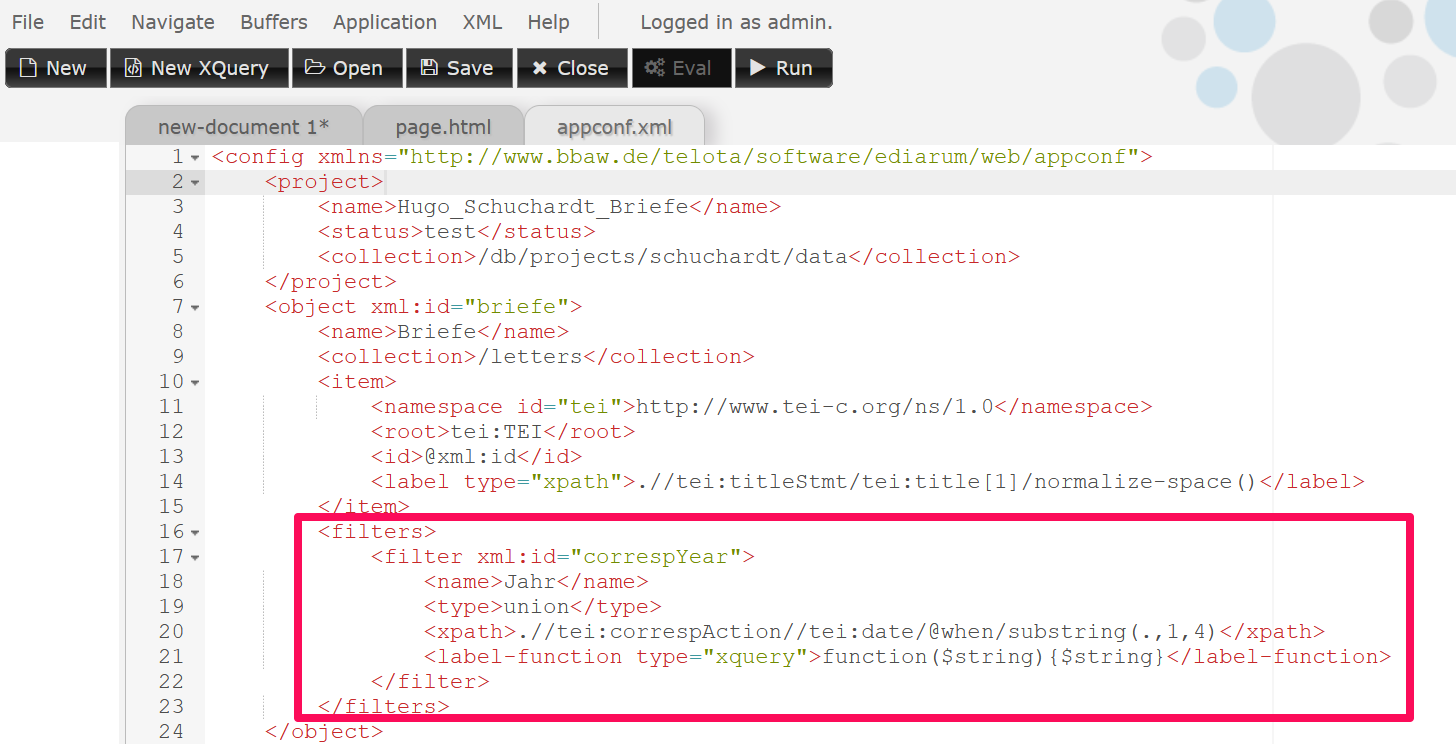
Anlegen des Jahreszahlen-Filters in der appconf.xml Wiederum legen wir den Namen des Filters fest, der auch so im Frontend angezeigt wird und geben mittels XPath-Ausdruck an, wonach gefiltert werden soll. In unserem Fall wird mittels XPath auf das Sendedatum der Briefe zugegriffen (z. B. “1879-01-01”) und mittels Substring-Funktion das Jahr ausgewählt, das dann auch im Filter klickbar sein wird. Innerhalb des Filters finden sich auch zwei neue Elemente:
<type>: Hier wird das Verhalten des Filters definiert, die möglichen Werte des Filter sind in der Dokumentation einsehbar. Wir wählen “union”, das bedeutet, dass im Filter mehrere Eigenschaften auswählbar sind und nur Dokumente, die zumindest eine dieser Eigenschaften haben, angezeigt werden. Wir können also z. B. zwei (oder mehr) Jahre auswählen und es werden folgend nur die Briefe angezeigt, die in einem dieser Jahre abgeschickt wurden.<label-function>: Hier kann optional eine XQuery-Funktion angegeben werden, mit der der im Filter angezeigte Wert (also z. B. die durch den XPath-Ausdruck ausgewählte Jahreszahl) noch weiter manipuliert werden könnte. Wir entscheiden gegen eine Manipulation und lassen den Wert durch die XQuery-Funktion unverändert zurückgeben.
Nach dem Speichern und der Rückkehr zur Indexseite der Briefe finden wir rechts neben der Liste der Briefe unseren Jahreszahl-Filter, der beim Scrollen auf die Schaltfläche “Alle” aufklappt.
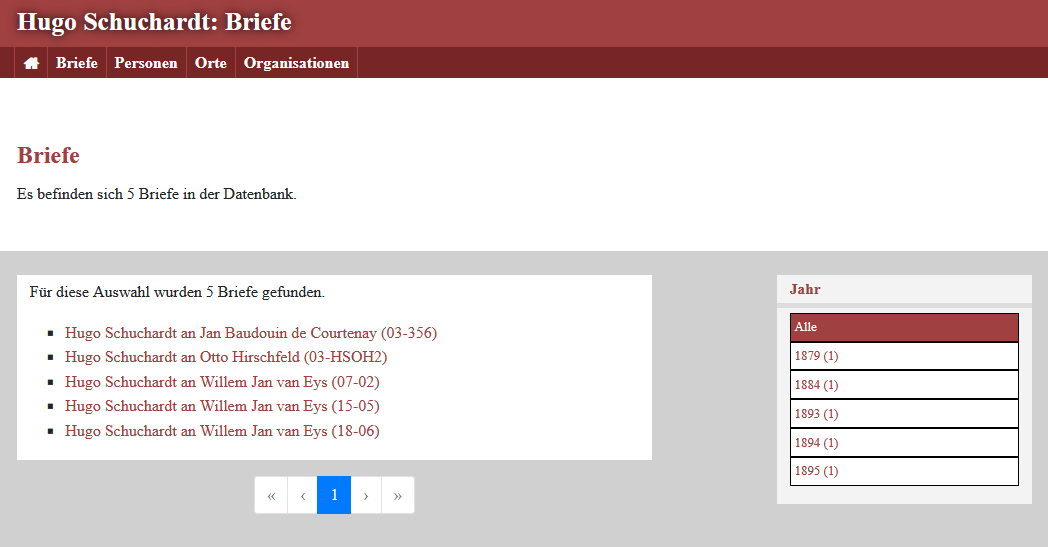
Der Jahreszahl-Filter In einem nächsten Schritt wollen wir einen Filter für die Personen anlegen, sodass wir diese alphabetisch nach Nachnamen filtern können.
<filters> <filter xml:id="alphabet"> <name>alphabetisch</name> <type>single</type> <xpath>.//tei:persName/tei:surname</xpath> <label-function type="xquery"> function($string){substring(normalize-space($string), 1,1)}</label-function> </filter> </filters>Als Wert von
<type>geben wir diesmal “single” an, da immer nur ein Buchstabe des Alphabets ausgewählt werden soll. Da wir nach Nachnamen filtern wollen, geben wir den entsprechenden XPath-Ausdruck an. Damit im Filter lediglich der Anfangsbuchstabe der Nachnamen angezeigt werden soll, greifen wir diesen mittels Substring-Funktion im XQuery-Ausdruck heraus. -
Einrichten einer XSL-Transformation für Briefe und Personen: Folgen wir momentan den Links auf der jeweiligen Indexseite der Briefe, Orte oder Personen, landen wir auf einer Detailansicht, bei der momentan lediglich der Hinweis angezeigt wird, dass eine XSL-Transformation eingerichtet werden soll.

Die Detailansicht eines Briefes Anlegen der XSL-Transformation für die Briefe: Um die Briefanzeige umzusetzen, muss zunächst ein XSLT-Stylesheet angelegt werden. Wir navigieren dazu in eXide innerhalb unserer App in den Ordner “resources” und danach in “xslt” und legen folgendes Stylesheet namens
briefe_details.xslan:<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:telota="http://www.telota.de" xmlns:tei="http://www.tei-c.org/ns/1.0" version="2.0" exclude-result-prefixes="tei"> <xsl:output method="html" doctype-system="http://www.w3.org/TR/html4/strict.dtd" doctype-public="-//W3C//DTD HTML 4.01//EN" indent="yes"/> <xsl:template match="/tei:TEI"> <div class="row"> <div class="col-md-12"> <xsl:apply-templates select="tei:text"/> </div> </div> </xsl:template> <xsl:template match="tei:p"> <p> <xsl:apply-templates/> </p> </xsl:template> <xsl:template match="tei:dateline|tei:opener|tei:salute|tei:signed"> <p> <xsl:apply-templates/> </p> </xsl:template> <xsl:template match="tei:hi"> <hi style="text-decoration: underline;"> <xsl:apply-templates/> </hi> </xsl:template> <xsl:template match="tei:persName"> <a href="$base-url/personen/{@ref/substring-after(., '#')}"> <xsl:apply-templates/> </a> </xsl:template> <xsl:template match="tei:placeName"> <a href="$base-url/orte/{@ref/substring-after(., '#')}"> <xsl:apply-templates/> </a> </xsl:template> <xsl:template match="tei:orgName"> <a href="$base-url/organisationen/{@ref/substring-after(., '#')}"> <xsl:apply-templates/> </a> </xsl:template> </xsl:stylesheet>Wir belassen es zunächst bei einem basalen Stylesheet, in dem alle
<p>-,<dateline>-,<opener>-,<salute>- und<signed>-Elemente in einem eigenen Absatz ausgegeben werden sollen. Zusätzlich wollen wir bei den in den Briefen vorkommenden Named Entities, also den Personen, Orten und Organisationen, eine Verlinkung zu den jeweiligen Einträgen in den Registern herstellen. Dazu nutzen wir bei den Personen folgendes Template:<xsl:template match="tei:persName"> <a href="$base-url/personen/{@ref/substring-after(., '#')}"> <xsl:apply-templates/> </a> </xsl:template>Wir greifen hier auf das
@refder Named Entities zu, greifen die ID, die sich hinter dem #-Zeichen findet, heraus (z. B. “P.HS”) und konstruieren einen Link auf den Eintrag im Personenregister.Im nächsten Schritt muss die
appconf.xmladaptiert werden, um das Stylesheet mit den Briefen zu verknüpfen. Dazu fügen wir folgendes XML-Snippet innerhalb des Brief-Objekts ein:<views> <view id="default"> <xslt>resources/xslt/briefe_details.xsl</xslt> <label>Standard</label> </view> </views>Die
appconf.xmlmit dem<view>-Element zum Einbinden des XSLT-Stylesheets: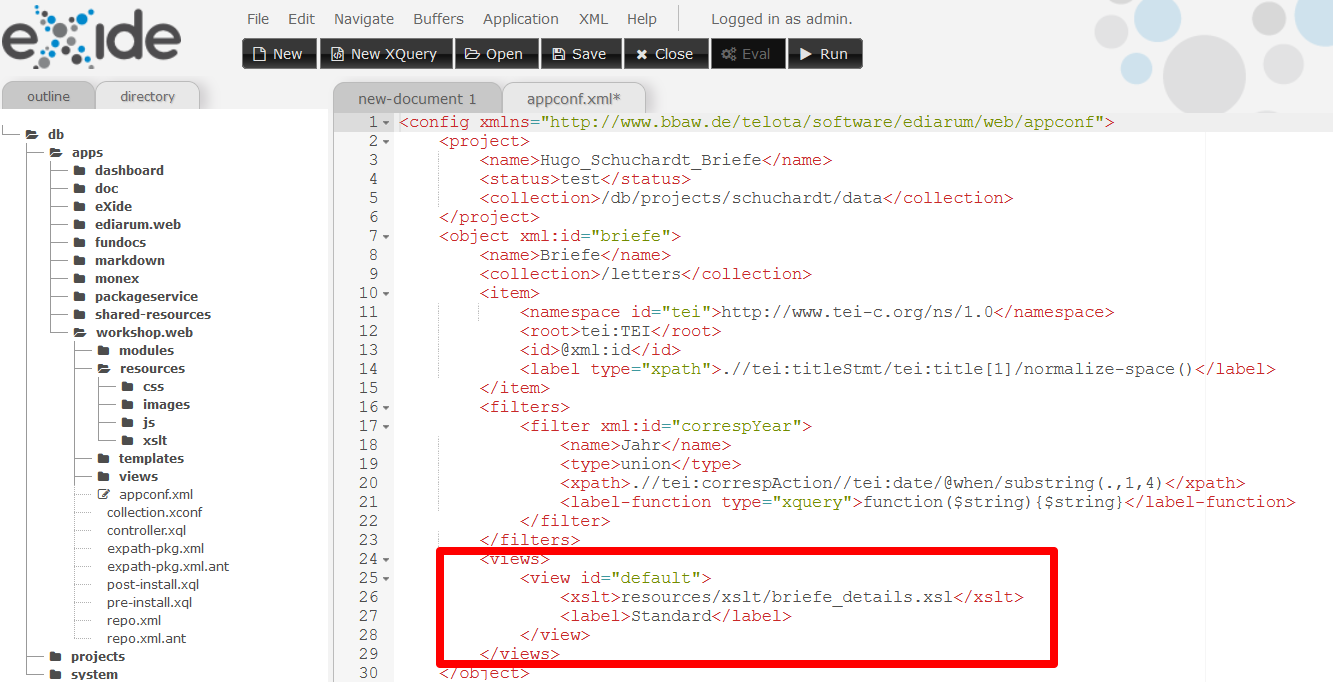
Einbinden des XSLT-Stylesheets Mit
view/@idwird die ID des Views angegeben, die auch von der API verwendet wird. Im<xslt>-Element wird der relative Pfad zum XSLT-Styleheet ausgehend von der App angegeben. Das<label>-Element gibt wiederum die Bezeichnung des Views, an die im Frontend angezeigt werden könnte.Rufen wir jetzt die Detailansicht eines Briefes auf, sehen wir, dass er gemäß dem Stylesheet transformiert und angezeigt wird:

Die Detailansicht eines Briefes Anlegen der XSL-Transformation für die Personen: Im nächsten Schritt legen wir im selben Ordner ein XSLT-Stylesheet namens
personen_details.xslan, um die Detailansicht der Personen einzurichten. Wir greifen hierbei auf das bereits vorhandene Stylesheet des Workshops zurück und passen es für unsere Zwecke an. Wir lassen Vor- und Nachnamen der Personen und den Verweis auf den Eintrag in der GND ausgeben. Wären in unserem Register noch weitere Informationen wie etwa Geburts- und Sterbedatum ebenfalls verzeichnet, könnten wir sie hier auch ausgeben lassen.<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:telota="http://www.telota.de" xmlns:tei="http://www.tei-c.org/ns/1.0" version="2.0" exclude-result-prefixes="tei"> <xsl:output method="html" doctype-system="http://www.w3.org/TR/html4/strict.dtd" doctype-public="-//W3C//DTD HTML 4.01//EN" indent="yes"/> <xsl:template match="/tei:person"> <div class="row"> <div class="col-md-12"> <h3>Grunddaten</h3> <div class="row"> <label class="col-sm-2">Vorname:</label> <div class="col-sm-10"> <xsl:value-of select="tei:persName/tei:forename"/> </div> </div> <div class="row"> <label class="col-sm-2">Nachname:</label> <div class="col-sm-10"> <xsl:value-of select="tei:persName/tei:surname"/> </div> </div> <h3>Verweise</h3> <ul> <xsl:apply-templates select="tei:idno"/> </ul> </div> </div> </xsl:template> <xsl:template match="tei:persName"> <li> <xsl:value-of select="."/> </li> </xsl:template> <xsl:template match="tei:idno"> <li> <a href="{.}"> <xsl:value-of select="."/> </a> </li> </xsl:template> </xsl:stylesheet>Zuletzt müssen wir wiederum die
appconf.xmladaptieren, um das Stylesheet mit den Personen zu verknüpfen. Dazu fügen wir folgendes XML-Snippet innerhalb des Personen-Objekts ein:<views> <view id="default"> <xslt>resources/xslt/personen_details.xsl</xslt> <label>Standard</label> </view> </views>Die
appconf.xmlmit dem<view>-Element zum Einbinden des XSLT-Stylesheets für die Personen: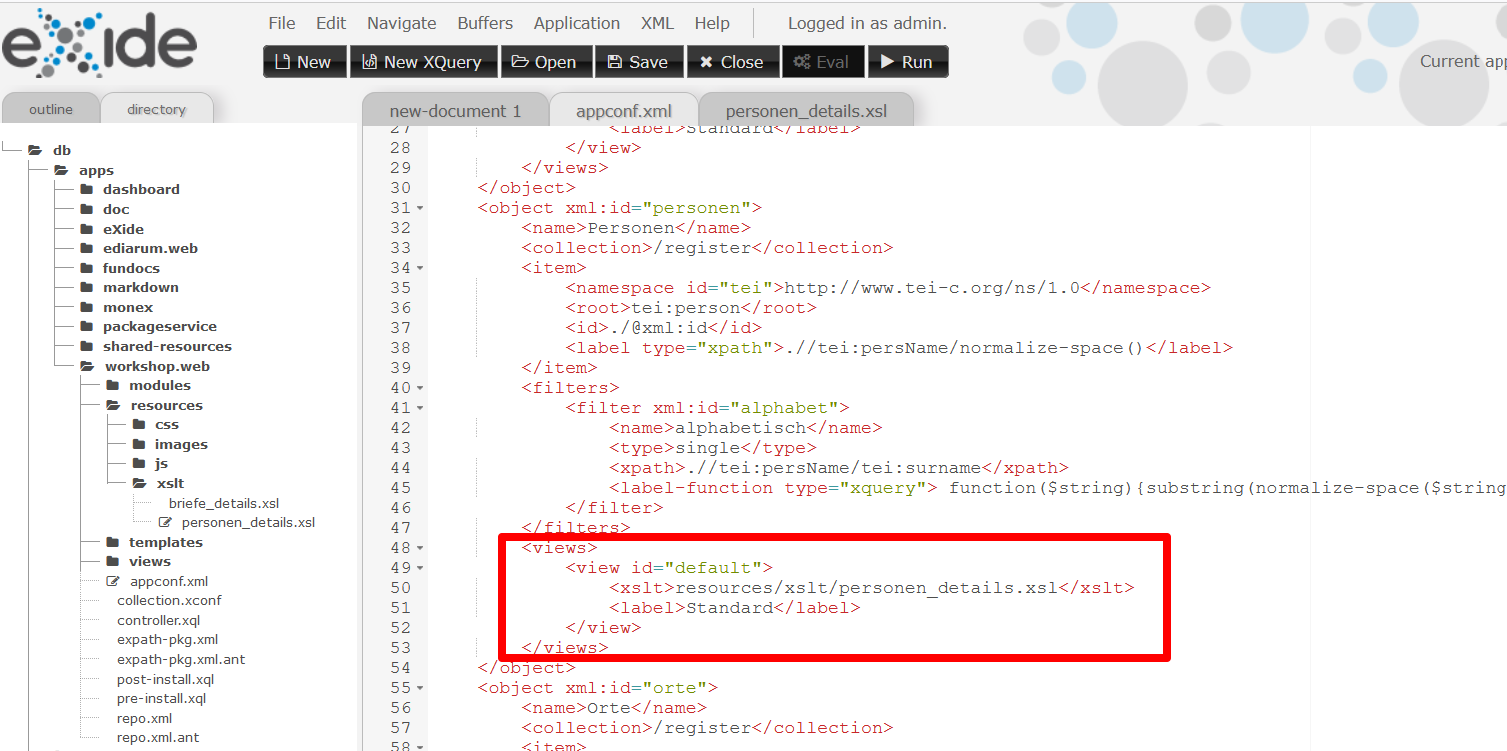
Das XML-Snippet für die Personen Folgen wir jetzt den Links auf die Personen in den Briefen oder klicken im Personenregister auf einen Eintrag, werden wir zur Detailseite der Person weitergeleitet:
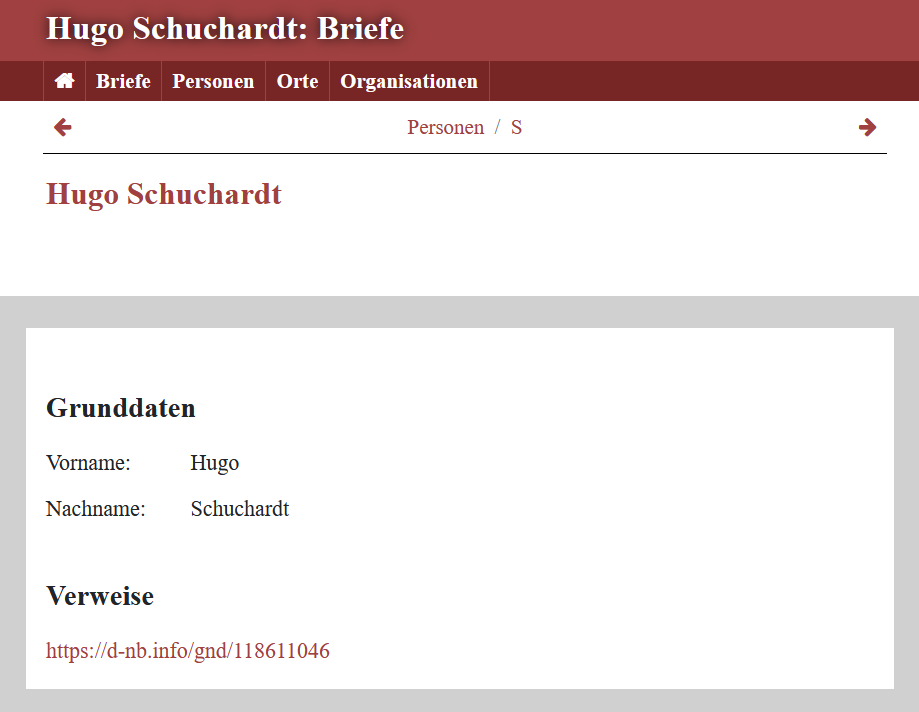
Die Detailansicht der Personen - Anpassen der Detailseite für Personen: In einem nächsten Schritt wollen wir die Detailseite für Personen anpassen und bei jeder Person anzeigen lassen, in welchem Brief sie genannt wird.
- Wir öffnen zunächst die Datei
controller.xqlund kommentieren folgende Codezeile ein:
edwebcontroller:view-with-feed("/personen/", "data-pages/personen-details.html", "object-type/personen/id/"),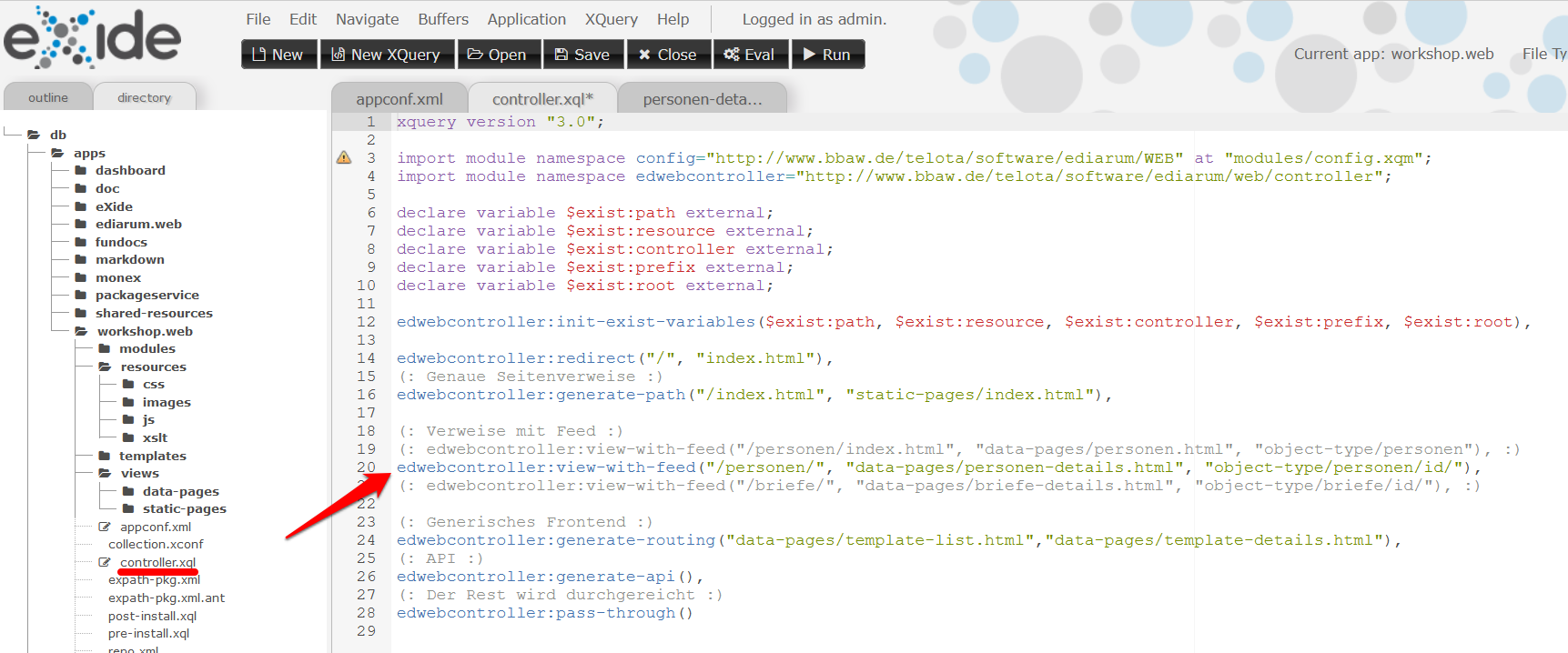
Bearbeitung der Datei “controller.xql” -
Danach navigieren in “views” → “data-pages”, kopieren die Datei
template-details.htmlund benennen sie inpersonen-details.htmlum.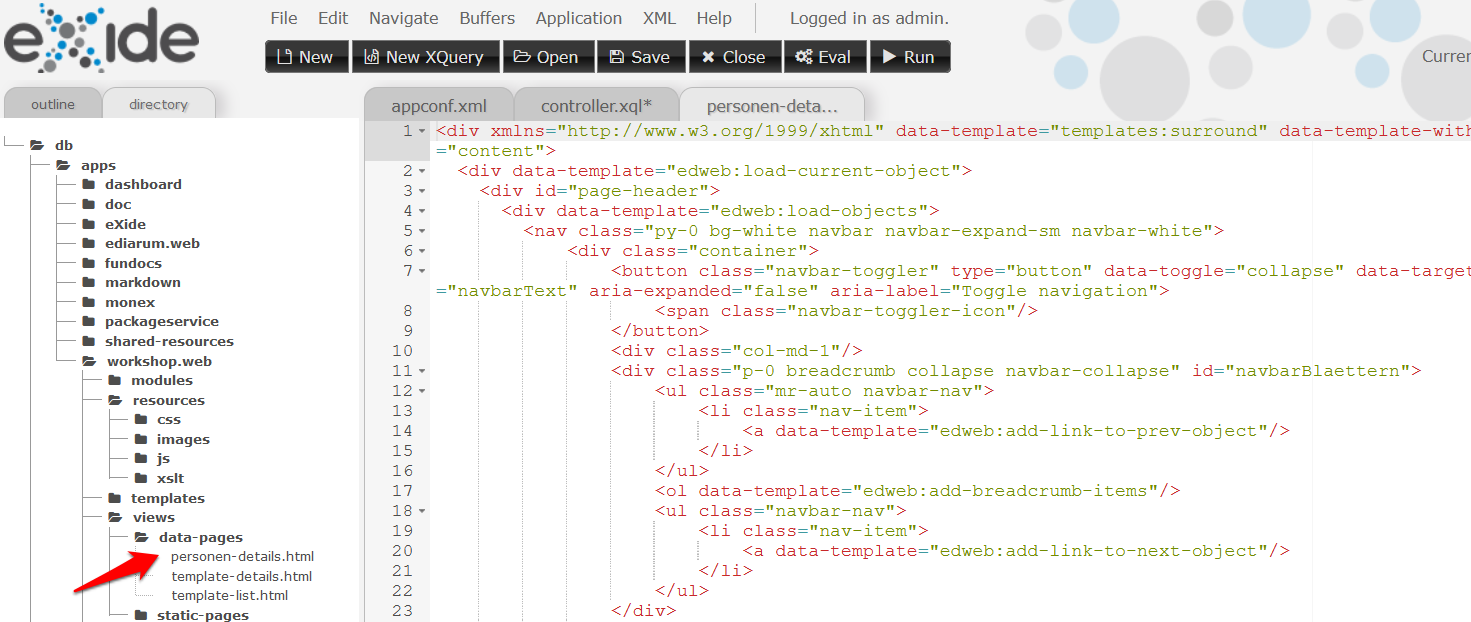
Erstellen der Datei “persons_details” -
Um die Personen mit den Briefen zu verknüpfen, in denen sie genannt werden, muss eine relation (Beziehung) in der
appconf.xmlangelegt werden. Wir fügen folgendes XML-Snippet als Geschwisterlement von<object>ein, das wir dem Dokumentation entnehmen und geringfügig für unsere Zwecke adaptieren:<relation xml:id="namensnennung" subject="personen" object="briefe"> <name>Namensnennung</name> <collection>/letters</collection> <item> <namespace id="tei">http://www.tei-c.org/ns/1.0</namespace> <root>tei:person/tei:persName</root> <label type="xquery">function ($node as node()) { "Nennung" }</label> </item> <subject-condition>function($this as map(*), $subject as map(*)) { $this?xml/@xml:id = $subject?id } </subject-condition> <object-condition>function($this as map(*), $object as map(*)) { $this?absolute-resource-id = $object?absolute-resource-id } </object-condition> </relation>Mit
@xml:idinnerhalb von<relation>wird der Name der Beziehung angegeben, der auch von der API verwendet wird. Mit@subjectwird die ID des Subjekts der Beziehung festgelegt, in unserem Fall die Personen, und mit@objectdas Objekt der Beziehung, in unserem Fall die Briefe. Mit<name>wird der Name des Beziehungstyps (“namensnennung”) definiert,<collection>gibt den relativen Pfad zur im<project>definierten Sammlung an, in der nach Beziehungen gesucht werden soll (im Ordner “letters”). Wiederum muss auch der TEI-Namespace in<namespace>angegeben werden. Mit<root>wird das Wurzelement jeder Beziehung angegeben, in unserem Fall bezieht sich der XPath-Ausdruck auf die im<standOff>der Briefe verzeichneten Personen. Bei<label>wird in unserem Fall ein XQuery-Ausdruck angegeben, um das Label der Beziehung zu festzulegen, in unserem Fall “Namensnennung”. Mit<subject-condition>und<object-condition>wird festgelegt, wie in einer Beziehung ein Subjekt mit einem Objekt verknüpft wird, dazu dienen XQuery-Funktionen, deren genauere Funktionsweise hier dokumentiert ist. Wichtig ist, dass wir die in der Codezeile$this?xml/@key = $subject?iddas@keydurch@xml:idersetzen, da dieses Attribut die ID der Personen enthält.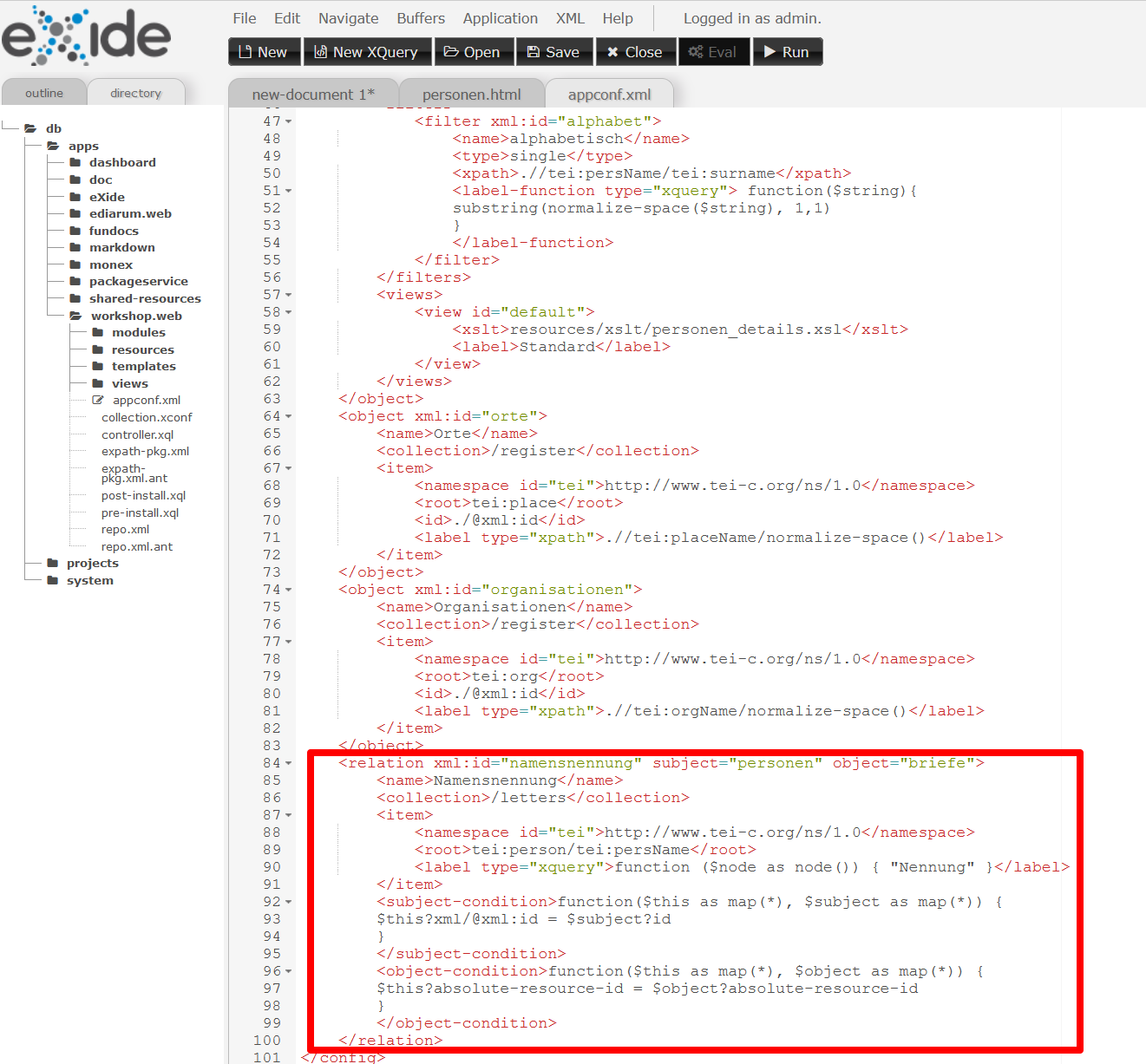
Das Definieren einer Beziehung. -
Nun müssen wir nur noch die Beziehung auf den Detailseiten der Personen anzeigen lassen. Wir öffnen dazu die Seite “personen-details” und fügen folgenden Code ein, dem wir dem Tutorial entnehmen und geringfügig adaptieren.
<div id="section/relations-msdesc"> <h3> Wird in den folgenden Briefen genannt:</h3> <div data-template="edweb:load-relations-for-subject" data-template-relation="namensnennung"> <div data-template="edweb:template-switch"> <switch> <span data-template="edweb:insert-count" data-template-from="relations" /> </switch> <p case="0">Keine Briefe vorhanden.</p> <span case="default"> <table class="table"> <thead> <tr> <th scope="col">Titel</th> <th scope="col">Kontextrolle</th> </tr> </thead> <tbody> <div data-template="templates:each" data-template-from="relations" data-template-to="item"> <tr> <td> <a data-template="edweb:template-detail-link" data-template-from="item"> <span data-template="edweb:insert-string" data-template-path="item?label" /> </a> </td> <td> <span data-template="edweb:insert-string" data-template-path="item?predicate" /> </td> </tr> </div> </tbody> </table> </span> </div> </div> </div>Die Seite
personen-details.htmlmit eingefügtem HTML-Snippet: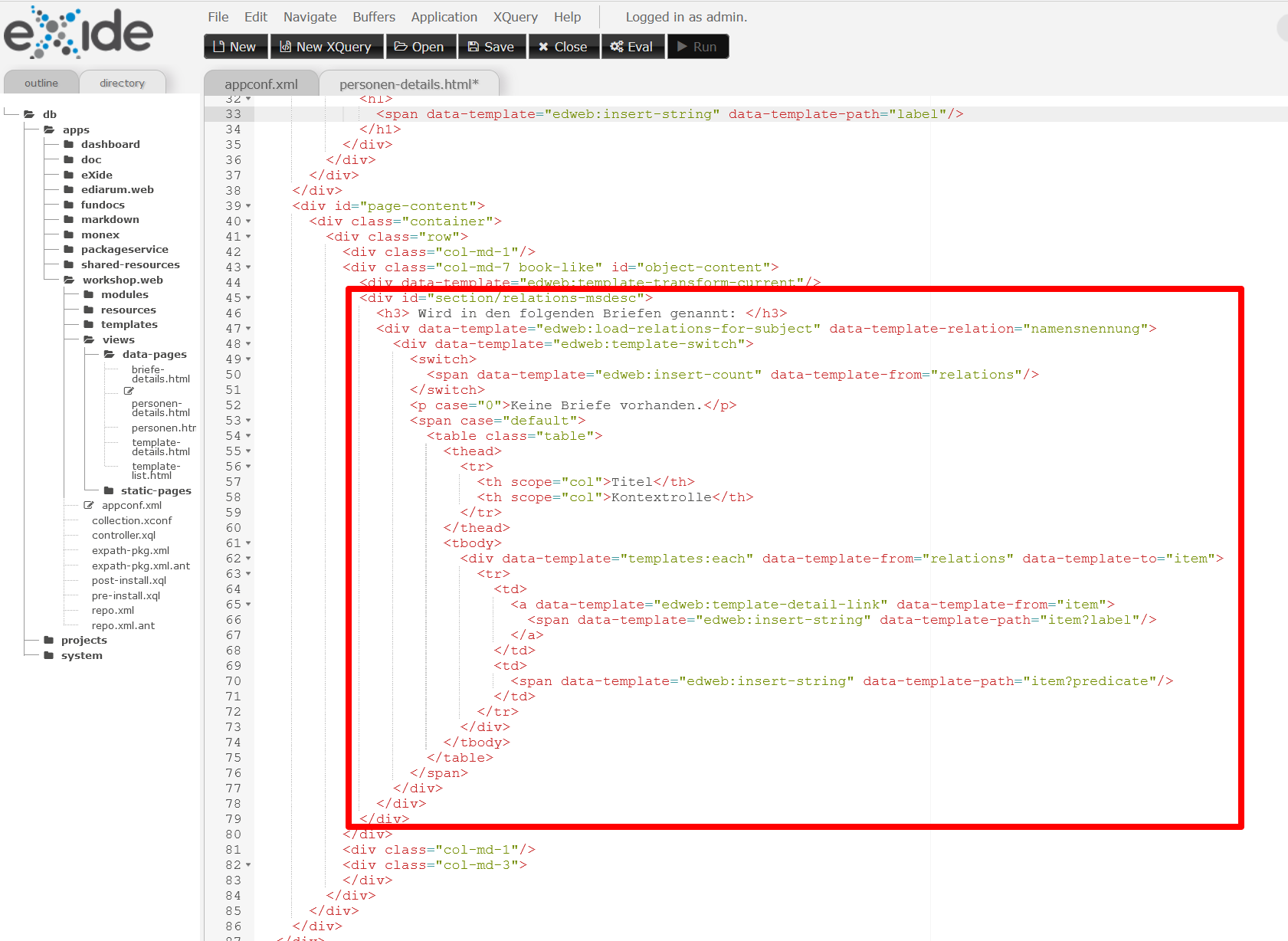
Anzeigen der Beziehung auf der Detailseite der Personen Öffnen wir jetzt eine Detailseite der Personen, werden die Briefe, in denen die Person genannt wird, in einer Tabelle angezeigt. Durch Klick auf die Links können wir zu den jeweiligen Briefen navigieren.
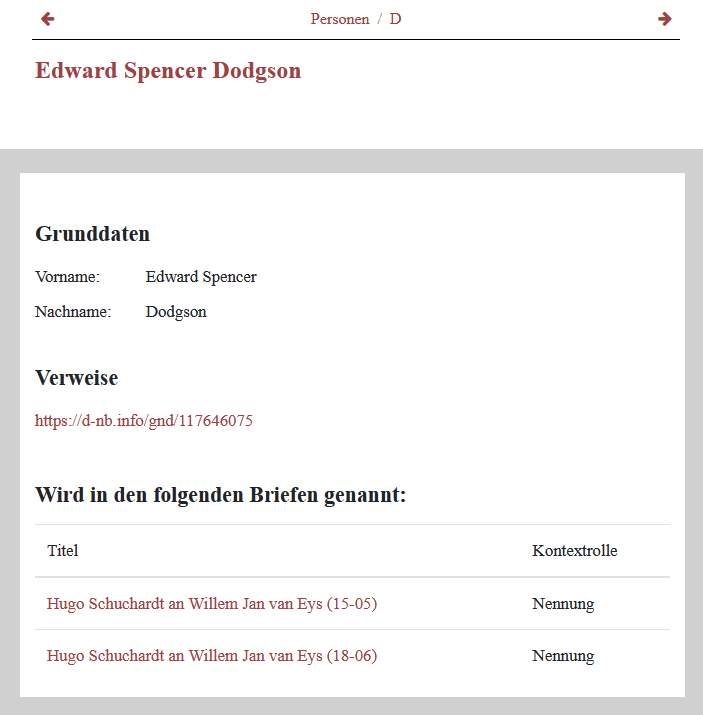
Die mit der Person verknüpften Briefe
- Wir öffnen zunächst die Datei
- Anpassen der Detailseite der Briefe und Einrichtung eines seitenweisen Blätterns: Momentan wird der gesamte Brieftext auf einer Seite angezeigt, was bei umfangreicheren Briefen ein längeres Scrollen bedeutet. Wir wollen deshalb ein seitenweises Blättern einzurichten, wozu einige Schritte erforderlich sind.
- Zunächst öffnen wir die
controller.xqlund fügen folgendes Codesnippet ein:
edwebcontroller:view-with-feed("/personen/", "data-pages/briefe-details.html", "object-type/briefe/id/"),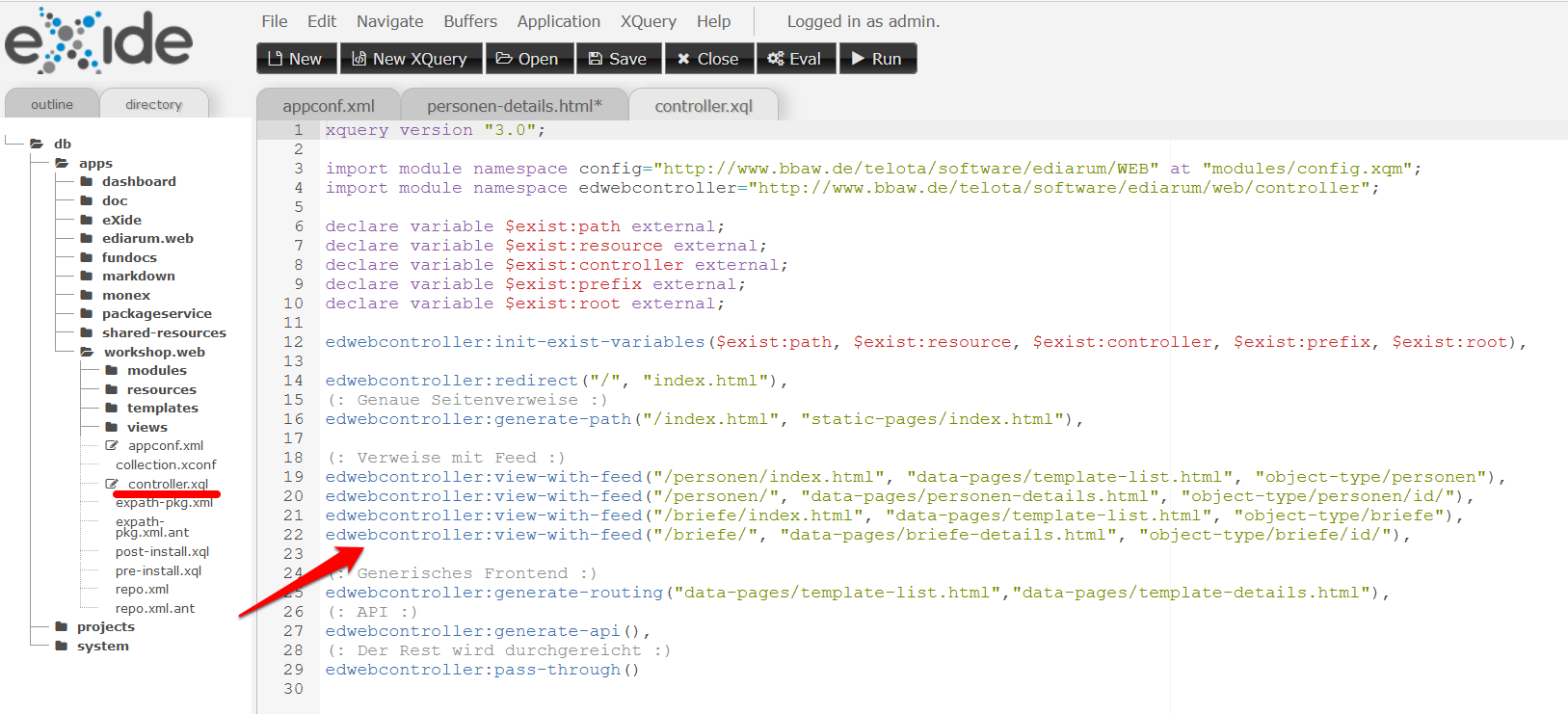
Einbinden der Detailseiten der Briefe -
Als nächstes müssen wir die Referenzierung der einzelnen Teile des Brief-Objekts, in unserem Fall der Seiten, einrichten. Dazu kehren wir zur
appconf.xmlund fügen innerhalb des<object>der Briefe folgendes XML-Snippet ein:<parts separator="." prefix="-"> <part xml:id="page" starts-with="p"> <root>tei:pb</root> <id>./@n</id> </part> </parts>Die Attribute
@separatorund@prefixmüssen verpflichtend angegeben werden. Ersteres legt fest, wie Teile und Unterteile im Falle von Verschachtelung abgeteilt würden (also z. B. durch Punkt wie in unserem Fall). Zweiteres legt fest, wie die Namespaces (@starts-with) von den Werten getrennt werden (also z. B. durch Bindestrich in unserem Fall wie etwa “page-1”).<root>legt wieder das Wurzelelement des Teils fest, in unserem Fall die Seiten (<tei:pb>),<id>gibt die ID des Teils an, in unserem Fall das@n.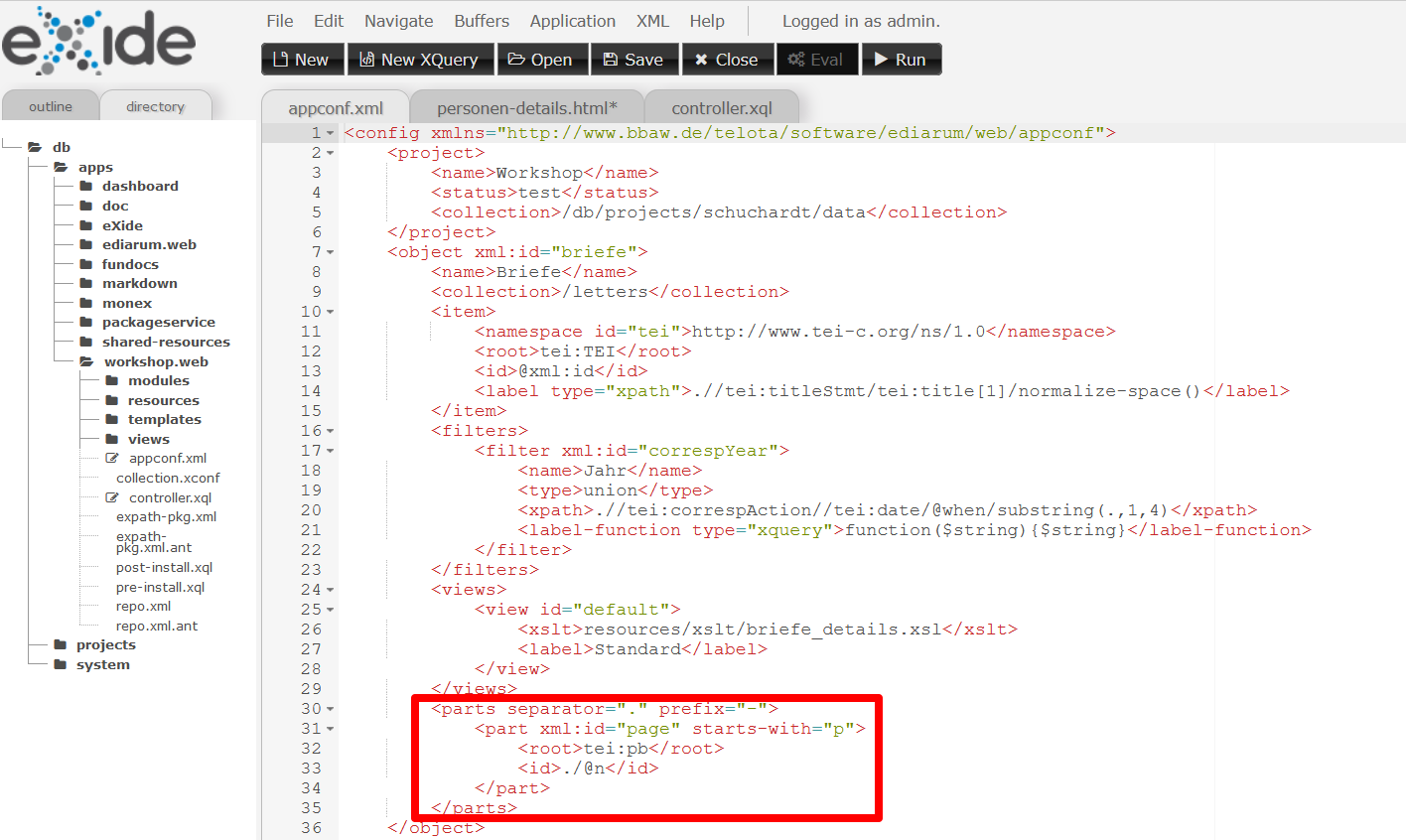
Unterteilung der Briefe in der in Seiten - Für das Umsetzen der seitenweisen Anzeige benötigen wir einige Funktionen, die wir dem Tutorial entnehmen können. Wir navigieren in den Ordner “modules”, entfernen die dort liegende Datei
app.xqlund ersetzen sie durch die gleichnamige im Tutorial vorhandene Datei. -
Nun müssen wir nur noch in “briefe_details.html” folgenden Codeblock ersetzen:
<div class="row"> <div class="col-md-1"></div> <div class="col-md-7 book-like" id="object-content"> <div data-template="edweb:template-transform-current"></div> </div> <div class="col-md-1"></div> <div class="col-md-3"></div> </div>Wir fügen stattdessen folgenden Code ein, den wir ebenfalls dem Tutorial entnehmen, wobei wir ihn für unsere Zwecke geringfügig anpassen, u. a. deshalb, da wir keine zweite XSLT-Datei haben, mit der wir weitere Informationen der Briefe ausgeben.
<div class="row" data-template="app:add-page-id"> <div class="col-md-1"/> <div data-template="app:load-parts" data-template-part="page"> <div data-template="app:load-page"> <div class="col-7 box whitebox page-height"> <div class="nav-scroller py-1 mb-2"> <nav class="nav d-flex justify-content-center"> <div data-template="app:select-page"/> </nav> </div> <div data-template="app:transform" data-template-from="part" data-template-resource="resources/xslt/briefe_details.xsl"/></div> <div class="col-1"/></div> </div> </div>Navigieren wir nun zu der Detailansicht eines Briefes, zeigt sich, dass nur die erste Seite angezeigt wird und ein Navigationsmenü zur Verfügung steht, mit dem zwischen den einzelnen Seiten umgeschaltet werden kann.
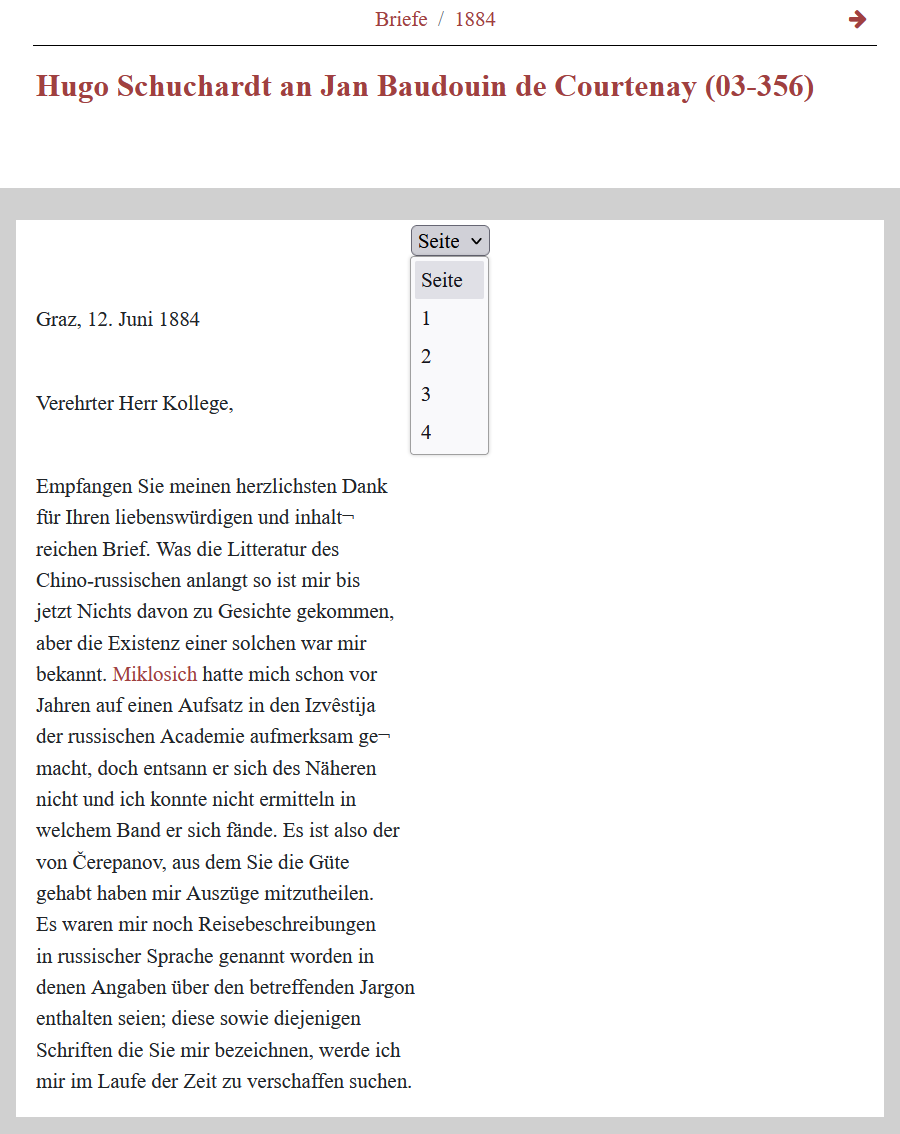
Das Menü zum Umschalten zwischen den einzelnen Briefseiten
- Zunächst öffnen wir die
-
Kontakt
Weblink: https://github.com/ediarum/ediarum.WEB
| Martin Fechner (Telota) | fechner@bbaw.de |
Ressourcen
Dokumentation
- GitHub (API.md, APPCONF.md, FEATURES.md, LIBRARIES.md, README.md)