
ba[sic?]
Allgemeine Beschreibung
ba[sic?], kurz für Better Authorities [Search, Identify, Connect], ist ein an der Sächsischen Akademie der Wissenschaften zu Leipzig entwickeltes Web-Tool für die Verknüpfung bestimmter Named Entities (Personen, Institutionen und Orte) mit von Normdatenanbietern wie der Gemeinsamen Normdatei (GND, bei Personen und Institutionen) oder GeoNames (bei Orten) bezogenen Normdaten. Das Tool bietet eine anwenderfreundliche Benutzeroberfläche und ist dank seiner intuitiven Bedienweise bereits nach einer sehr kurzen Einarbeitungszeit gut nutzbar.
Im Rahmen dieses Tooldocs wurde die Webversion des Tools getestet, es kann allerdings auch über GitHub bezogen und dann in einem gewissen Ausmaß an die eigenen Erfordernisse angepasst werden.
Anwendungsbereiche
- Verknüpfung der importierten Named Entities mit von Normdatenanbietern (GND und GeoNames) bezogenen Identifiern
- Optionale Anreicherung der importierten Named Entities mit weiteren Informationen entweder durch Übernahme der von den Normdatenanbietern bezogenen Daten (etwa biografische bei Personen oder Längen- und Breitengrade bei Orten) oder durch manuelle Eingabe dieser
Funktionsübersicht
- Zusammenführung der importierten Named Entities mit von Normdatenanbietern (GND und GeoNames) abgefragten Identifiern
- Zuweisung eines Status (z. B. “safe”, “incorrect”, “unavailable”) zu den Treffern
- Anreicherung der Named Entities mit weiteren von den Normdatenanbietern bezogenen Informationen (etwa Lebensdaten bei Personen oder Längen- und Breitengrade bei Orten)
- Bereinigung des importierten Datensatzes, z. B. durch Löschen oder Auszeichnung mehrfach vorhandener Einträge als Dubletten
Voraussetzungen
Da jedes Projekt unterschiedliche Anforderungen mit sich bringt, sollen nachfolgend mögliche Vor- und Nachteile des Tools aufgelistet werden, die während der Durchführung des jeweiligen Beispielprojekts festgestellt wurden.
Erforderliche Kenntnisse
Benötigte Software
- Stabile Internetverbindung
- Webbrowser
Tool-Kompatibilität
| IIIF | Transkribus | FromThePage | ediarum | FairCopy | teiPublisher | ediarum.WEB | |
| ba[sic?] | ❌ | ❌ | ❌ | ❌ | 🦄 | ❌ | ❌ |
Kostenübersicht
- kostenlos
Möglichkeiten & Grenzen
Da jedes Projekt unterschiedliche Anforderungen mit sich bringt, sollen nachfolgend mögliche Vor- und Nachteile des Tools aufgelistet werden, die während der Durchführung des jeweiligen Beispielprojekts festgestellt wurden.
Stärken
- Die Nutzung von ba[sic?] erweist sich als einfach und intuitiv, für die Nutzung des Tools an sich sind keine über EDV-Grundkenntnisse hinausgehende Kenntnisse notwendig
- Die importierten Daten werden nicht auf einen Server übertragen, sondern im Local Storage des Browsers bzw. Geräts gespeichert, wodurch die Datensicherheit gewahrt ist
- Nicht nur die Links auf die Einträge zu den Named Entities in den Normdatenbanken können in den lokalen Datensatz der Entität kopiert werden, sondern auch etwaige weitere in den Einträgen vorhandene Informationen (etwa biografische Daten bei Personen oder Längen- und Breitengrade bei Orten). Diese Daten werden beim Export ebenfalls berücksichtigt und ausgegeben (siehe Ende Abschnitt 3).
- Es kann jederzeit ein Backup des Arbeitsfortschritts in Form einer JSON-Datei erstellt werden, die auch wieder importiert werden kann. Diese Datei kann mit anderen am Projekt Beteiligten geteilt werden, sodass ein gewisses Maß an kollaborativem Arbeiten möglich ist.
Herausforderungen & Probleme
- Die Daten müssen für den Import in bestimmten Dateiformaten vorliegen: Entweder muss es sich um CSV-Dateien (generisch oder im CMI-Format (Konvertierungstool)) oder XML-Dateien handeln, d. h. es ist wahrscheinlich ein gewisses Maß an Preprocessing der zu importierenden Daten erforderlich
- Aktuell werden lediglich Identifier der Gemeinsamen Normdatei (Personen und Organisationen) und GeoNames (Orte) unterstützt. Wenn in den Einträgen dieser Services Verlinkungen auf anderen Normdatenanbieter (wie z. B. VIAF oder Wikidata) vorhanden sind, werden diese zwar ausgegeben und sie sind in der Tabellenansicht (siehe Abbildung 7) sicht- und klickbar, können allerdings nicht in den lokalen Datensatz der Entität kopiert werden
- Die Datenfelder der weiterführenden Informationen zu den Named Entities sind vorkonfiguriert (bzw. bedingt durch die Datenfelder in den Einträgen der Normdatenanbieter), sie können nicht umbenannt werden und es können auch keine eigenen Datenfelder hinzugefügt werden
- Export der Daten ist nur als JSON-Datei oder als Merge mit einer bereits bestehenden CSV-Datei (generisch oder im CMI-Format (Konvertierungstool)) möglich
Einrichtung & Erste Schritte
Anhand eines Beispielprojekts, in dem mit handgeschriebenen Briefen des Linguisten Hugo Schuchardt (1842-1927) aus dem 19. Jahrhundert bzw. 20. Jahrhundert gearbeitet wird, soll nachfolgend ein möglicher Arbeitsablauf mit dem Normalisierungstool ba[sic?] beschrieben werden. In einem ersten Schritt wurden die handgeschriebenen Briefe bereits mittels des OCR/HTR-Tools Transkribus Lite transkribiert. Danach wurde der TEI/XML-Export in den TEI/XML-Editor FairCopy ingestiert und tiefergehend annotiert, wobei Named Entities wie Personen, Orte und Organisationen berücksichtigt und im <standOff> der einzelnen Briefe verzeichnet wurden. Im Zuge der Transition wurde in einer ersten Phase unter Verwendung der Programmiersprache Python eine Indexdatei erstellt, in der alle Named Entities verzeichnet sind. Ziel des hier dokumentierten Arbeitsschrittes ist es nun, diese Named Entities mit Normdaten (GND- und GeoNames-Links) anzureichern. Danach sollen diese in der zweiten Phase der Transition die Named Entities im <standOff> der Briefe mit diesen neu erhobenen Normdaten verknüpft werden.
1. Aufrufen der Homepage
- Da es sich bei ba[sic?] eben um eine Browseranwendung handelt, entfällt ein etwaiger Installationsschritt und es muss lediglich die Homepage https://basicdemo.saw-leipzig.de/ des Services aufgerufen werden. Auf dieser findet sich eine kurze Beschreibung des Tools und eine Schnellstartanleitung (“Quick Start Guide”).
![Die Startseite von ba[sic?]](../data/pipelines/pipeline_2/basic/img/welcome_page.png)
- Die Arbeitsschritte mit ba[sic?] können gemäß dieser Anleitung wie folgt zusammengefasst werden:
- Auswahl der Kategorie an Named Entities, die mit Normdaten angereichert werden sollen (Personen, Orte oder Organisationen)
- Anlegen eines neuen Datensatzes
- Import oder manuelles Hinzufügen der mit Normdaten anzureichernden Entitäten zum Datensatz
- Automatische Suche nach möglichen Entsprechungen zu den Daten oder manuelles Hinzufügen der Links und gegebenenfalls weiterer Informationen
- Export des angereicherten Datensatzes
2. Anlegen eines neuen Datensatzes und Import der Daten
- Um einen Datensatz anzulegen, müssen wir uns zunächst für eine der drei in ba[sic?] auswählbaren Kategorien an Named Entities entscheiden: Personen, Orte oder Organisationen. Wir entscheiden uns für Personen und wählen daher in der linken oberen Ecke auf der Startseite (siehe Abb. 1) “Persons” aus.
- Zunächst müssen wir dem Datensatz einen Namen geben (wir entscheiden uns für “Schuchardt_Personen”), danach können wir ihn durch Betätigung der Plus-Buttons anlegen. Es können parallel mehrere verschiedennamige Datensätze angelegt werden, zwischen denen über die Schaltfläche “Current Dataset” gewechselt werden kann. Gleich unterhalb des ausgewählten Datensatzes werden Datum und Uhrzeit der letzten Änderung des Datensatzes angezeigt.
- Nun können wir unter “Actions” die Dateien zum Import auswählen. Es werden nur zwei Dateitypen unterstützt: CSV-Dateien (generisch oder im CMI-Format (Konvertierungstool)) oder XML-Dateien. Da unsere Named-Entity-Daten, die wir im Zuge der Transition von FairCopy zu ba[sic?] erzeugt haben, im XML-Format vorliegen, entscheiden wir uns für diese Option und laden unsere XML-Datei hoch.
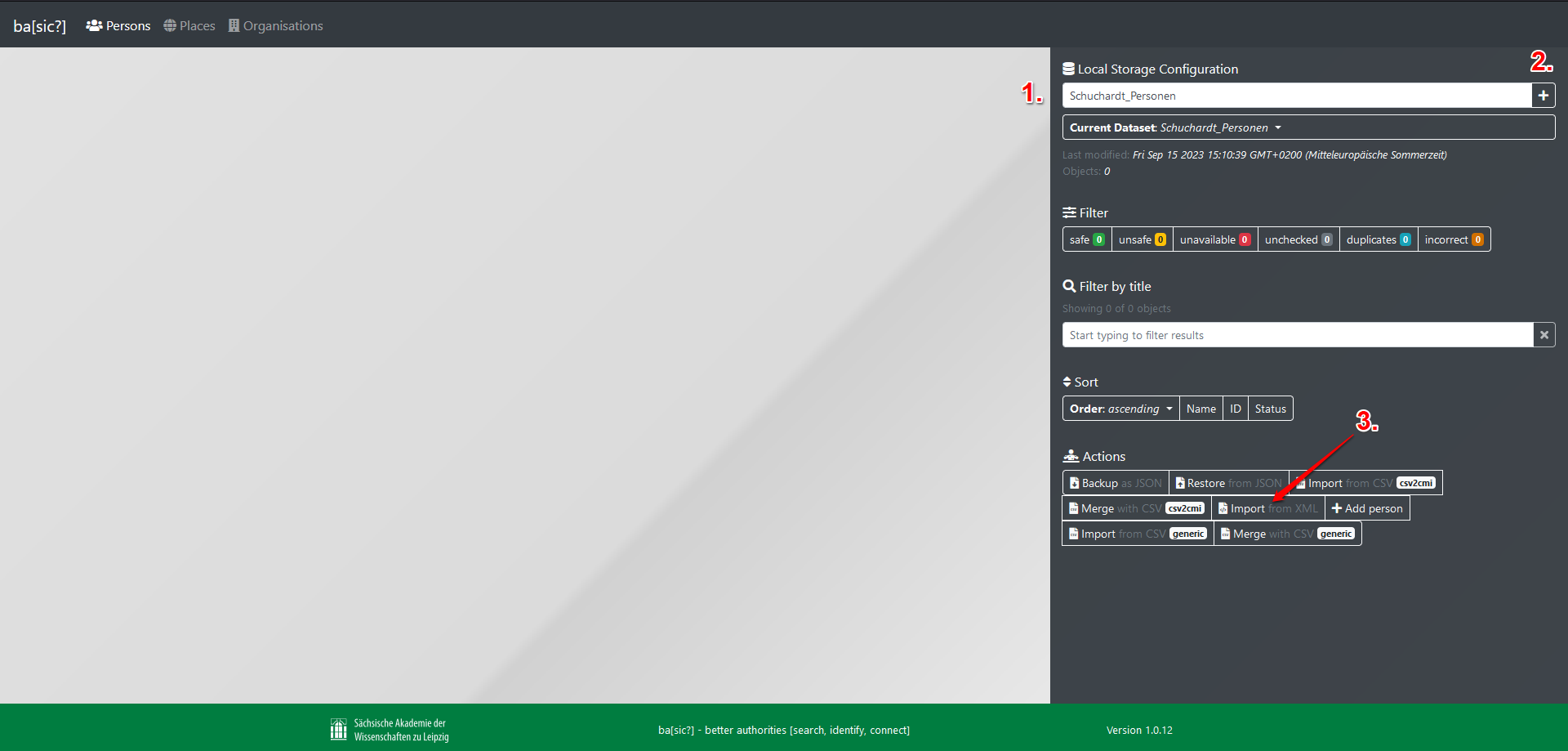
- Im Importfenster wählen wir zunächst den Speicherort unserer Datei aus. Als nächstes behalten wir die Standardeinstellung bei, allen zu importierenden Entitäten den Status “unchecked” zuzuweisen. Weiters müssen wir einige Auswahlentscheidungen treffen, die durch den Aufbau der von uns zu importierenden Daten bedingt werden. Unsere XML-Datei verfügt über folgende Struktur, hier exemplarisch veranschaulicht an einem Eintrag in der
<listPerson>.
<listPerson>
<person>
<persName xml:id="P.HS">Hugo Schuchardt</persName>
</person>
</listPerson>
Orte und Organisationen sind in mit den ihnen jeweils entsprechenden TEI-Elementen (also z. B. <listPlace>, <place> und <placeName>) verzeichnet. Zunächst müssen wir den Namen des XML-Elements (“Element name”) angeben, der die Objektinformationen enthält. Standardmäßig ist <persName> vorkonfiguriert, wir können die Auswahl also beibehalten. Eine Anpassung müssen wir nur beim Namen des ID-Attributes (“ID attribute name”) vornehmen: Wir ändern “id” auf “xml:id” ab, sodass unsere Entitäten samt @xml:id eingelesen werden können. Nun werden uns in der Vorschau bereits alle erkannten Entitäten angezeigt, nicht gewünschte könnten wir durch Abwahl der Kästchen vom Import ausschließen. Wir entscheiden uns dafür, alle durch einen Klick auf “Import objects” zu importieren.
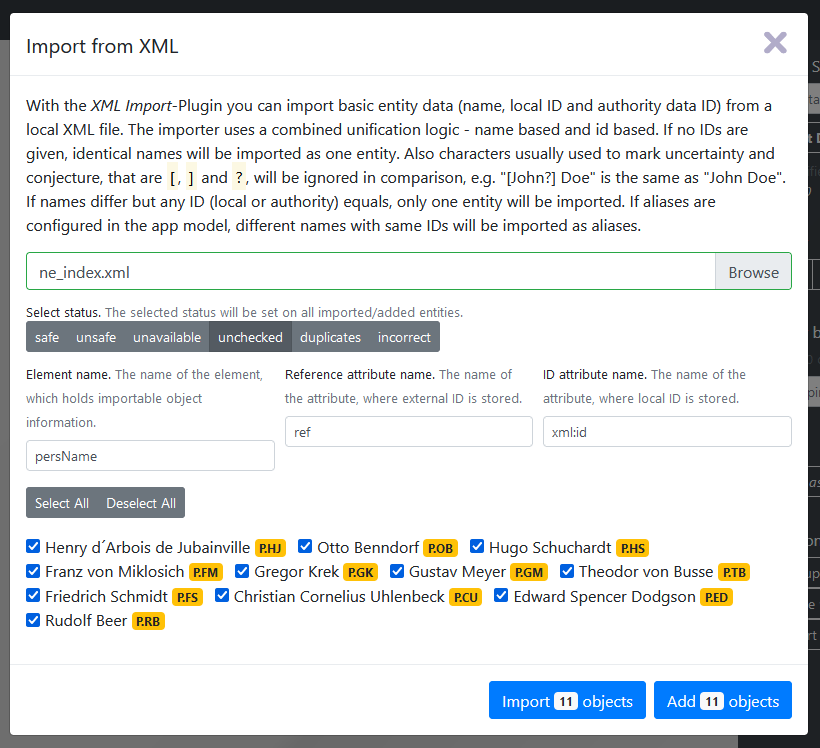
3. Anreicherung mit Normdaten
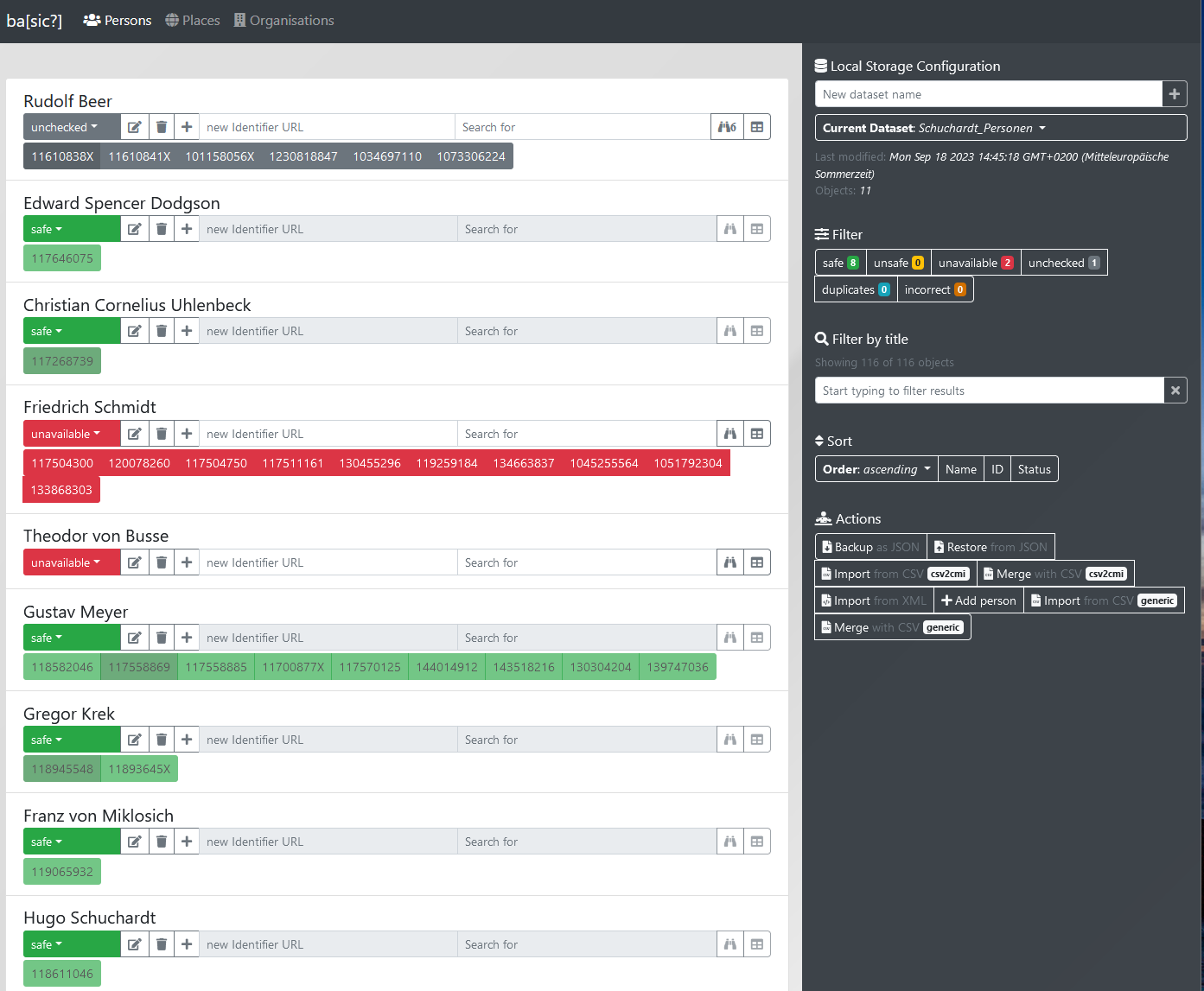
- Nun erhalten wir eine Liste der Personen, die wir rechts nach Namen, ID oder Status sortieren könnten.
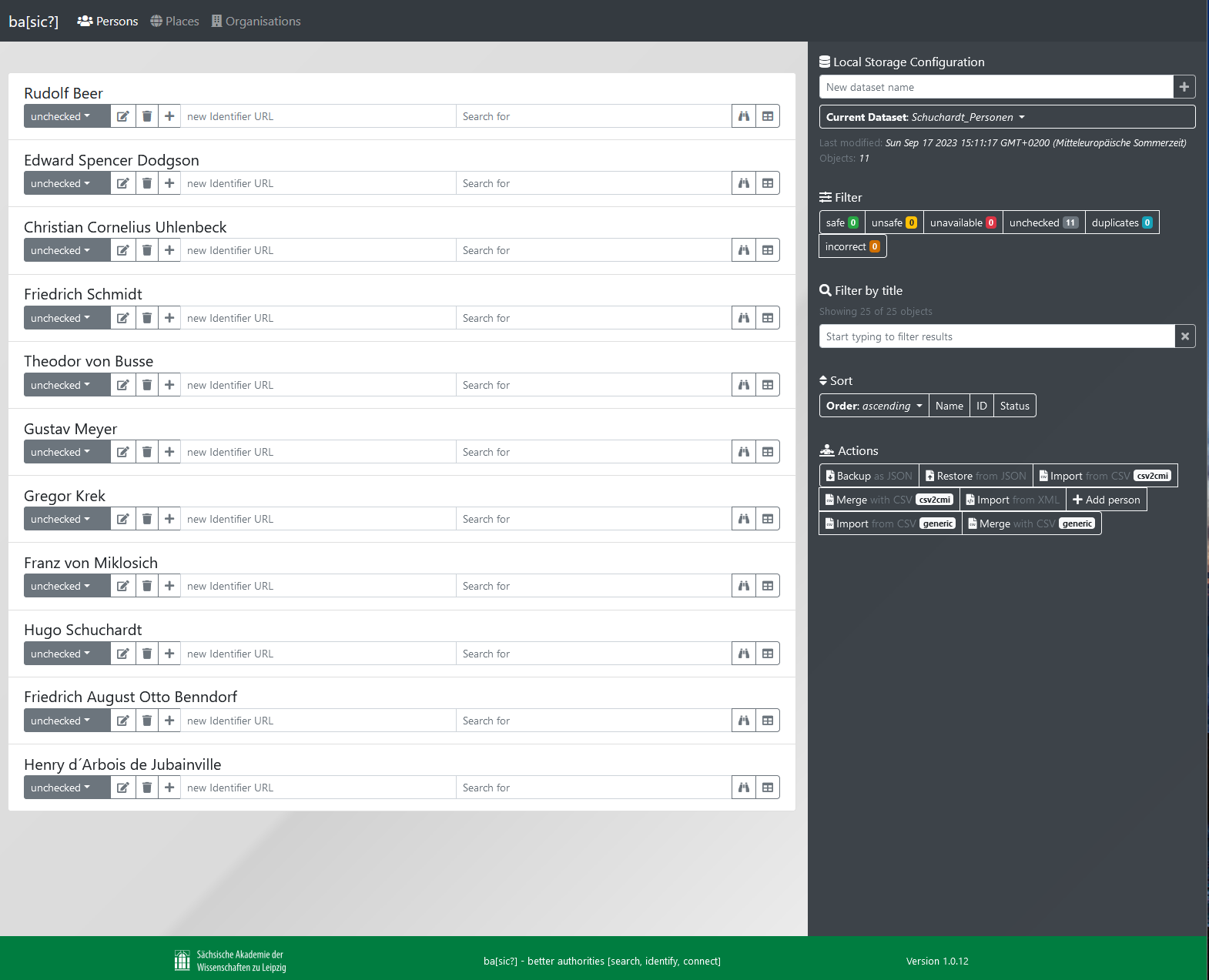
-
Optionen bei den einzelnen Entitäten:

Die Optionen bei den einzelnen Entitäten - Status-Reiter: Über den Status-Reiter kann der Status der Entität festgelegt werden: “safe”, “unsafe”, “unavailable”, “unchecked”, “duplicates” und “incorrect”
- Stift- und Papiersymbol: Über diese Option können der Entität manuell Daten (im Fall von Personen biografische Daten wie Geburts- und Sterbeort oder Beruf) hinzugefügt werden. Welche Felder vorhanden sind, ist vorkonfiguriert bzw. durch die in den Einträgen des jeweiligen Normdatenanbieters vorhandenen Datenfelder bedingt
- Papierkorbsymbol: Über dieses Symbol kann die Entität gelöscht werden. Das Löschen einer Entität kann nicht wieder rückgängig gemacht werden
- Plussymbol: Über dieses Symbol kann der Entität über das Textfeld rechts daneben manuell ein Identifier hinzugefügt werden. Im Fall von Personen wird nur ein GND-Identifier akzeptiert
- Fernglassymbol: Über das Fernglassymbol wird der jeweilige Normdatenanbier automatisch nach dem Namen der Entität durchsucht. Alternativ kann im vorhergehenden Textfeld ein Namen eingeben werden, nach dem stattdessen gesucht werden soll
- Tabellensymbol: Über das Tabellensymbol können nach der Suche die Daten der möglichen Treffer verglichen werden (siehe übernächster Punkt) und diese in den eigenen Datensatz übernommen werden (siehe Ende Abschnitt 3)
-
Wir entscheiden uns dafür, automatisch nach dem jeweiligen Personennamen zu suchen und klicken daher auf das Fernglas-Symbol. Nach wenigen Sekunden werden die Ergebnisse in Form einer Reihe an GND-Identifiern angezeigt.

- Bei der Suche in der GND nach den Personen werden eben nicht nur die Identifier zurückgegeben, sondern auch eine Reihe an biografischen Daten wie Geburts- und Sterbedatum, Beruf oder Affiliation, die für die Auswahl des korrekten Matches aus den möglichen Treffern notwendig sind. ba[sic?] bietet zwei Möglichkeiten, sich diese Daten anzeigen zu lassen: Bewegt man die Maus über einen Identifier, werden diese sie in einer Sprechblase angezeigt. Da so allerdings immer nur die Daten einer Person angezeigt werden können, aber kein vergleichendes Betrachten aller Treffer möglich ist, entscheiden wir uns für die Tabellenansicht (Tabellen-Symbol neben dem Fernglas-Symbol, siehe Abb. 6), die uns diesen Vergleich erlaubt.
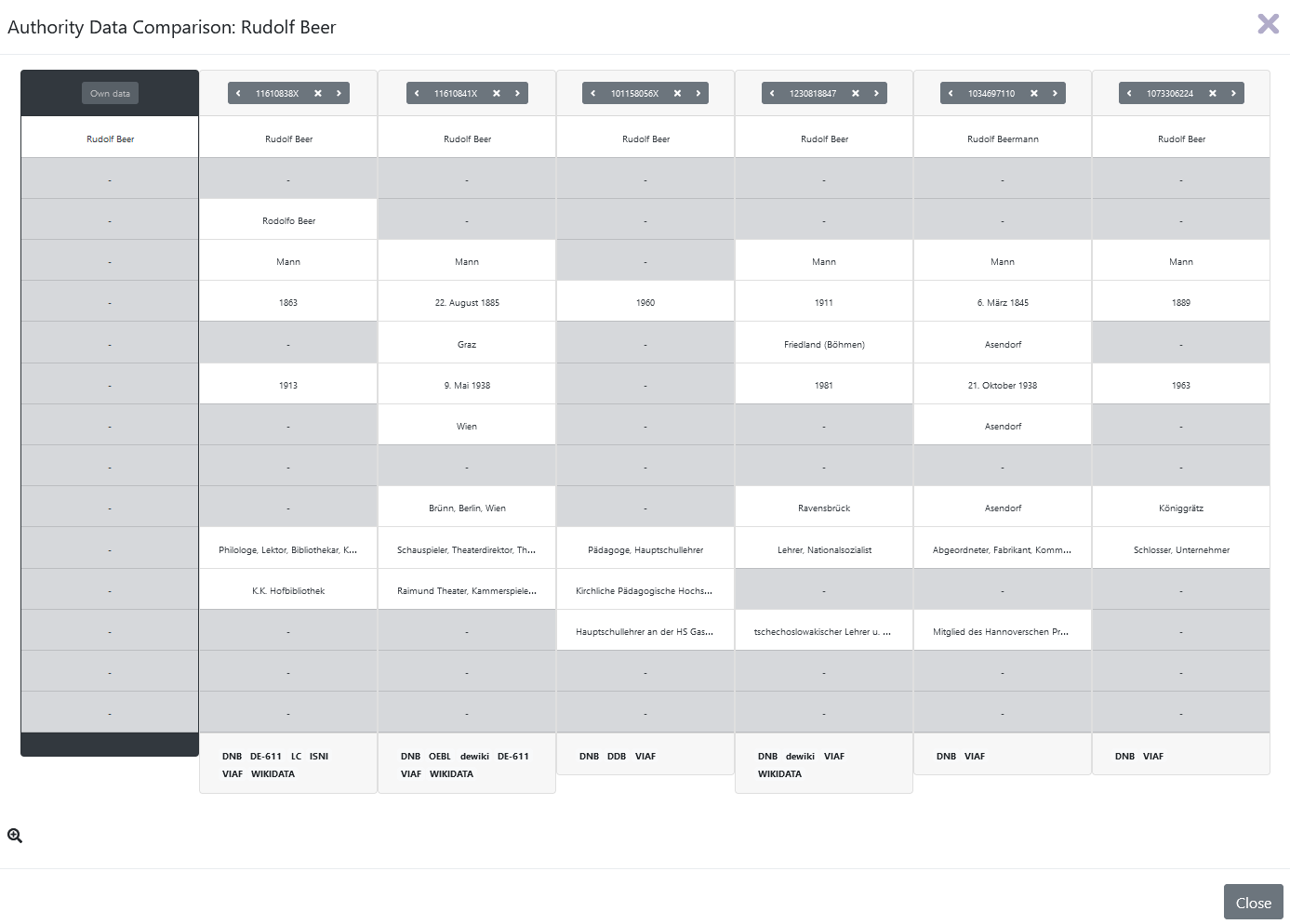
- Um den richtigen Treffer auszuwählen, müssen uns natürlich einige biografische Daten der gesuchten Person bekannt sein. Normalerweise würden diese im Zuge des Projekts erhoben werden, wir können diesen Schritt überspringen und auf das Personenregister des Hugo-Schuchardt-Archivs zugreifen. Dort suchen wir den Eintrag zu “Beer, Rudolf” heraus und greifen auf dessen Personenbeschreibung zu. Durch Abgleich mit diesem Eintrag können wir feststellen, dass es sich bereits beim ersten Ergebnis (Identifier “11610838X”) um den von uns gesuchten “Rudolf Beer” handelt. Wir klicken in der Kopfzeile der Tabelle auf den Identifier, dadurch wird dieser Eintrag als Match ausgewählt, was durch die türkise Färbung der Spalte angezeigt wird. Durch einen Klick auf “Close” bestätigen wir die Auswahl.

- Wir kehren nun zur Listenansicht zurück und können den Status beim Eintrag “Rudolf Beer” auf “safe” setzen, da es sich um das korrekte Match handelt. Der Eintrag färbt sich nun grün ein, wobei die etwas dunklere Färbung des ersten Identifiers anzeigt, dass dieser als Match ausgewählt wurde.

- Auf diese Weise arbeiten wir uns durch die Personenliste. In den meisten Fällen lässt sich durch Abgleich mit den Einträgen des Hugo-Schurchardt-Archivs das korrekte Match ermitteln, nur in drei Fällen stoßen wir auf Schwierigkeiten:
- Friedrich Schmidt: Zu Friedrich Schmidt findet sich keine Personenbeschreibung im Hugo-Schuchardt-Archiv. Da eine Durchsicht der biografischen Daten der möglichen Treffer auch kein passendes Match nahelegt und da wir vor allem nicht spekulieren wollen, sondern nur exakte Matches in unseren Daten haben wollen, markieren wir den gesamten Eintrag als “unavailable”.
- Theodor von Busse: Hier gibt die Suche mit ba[sic?] keinen einzigen Treffer zurück, weshalb wir den Eintrag als “unavailable” markieren.
- Gregor Krek: Hier werden zwei mögliche Treffer zurückgegeben. Auch hier finden wir keine Personenbeschreibung, da Hugo Schuchardt Krek allerdings in dem Brief, in dem dieser genannt wird, als “Kollege” bezeichnet, entscheiden wir uns im Zusammenspiel mit den biografischen Informationen (u. a. Wirkungsort Graz, Beruf Philologe und Slawist) dafür, den ersten Treffer als “safe” zu markieren.
- Exkurs: Hinzufügen weiterer Informationen zu den Entitäten: Durch das Auswählen des korrekten Matches wird den Entitäten lediglich der Link auf den jeweiligen Normdateneintrag hinzugefügt. Je nach Projekt kann es aber erwünscht sein, dem lokalen Datensatz weitere Informationen hinzuzufügen, etwa biografische Daten im Falle der Personen.
- Dafür muss zunächst der Status des Eintrags von “safe” auf einen der anderen umgestellt werden, da ansonsten kein Kopieren der Informationen möglich ist. Danach können die abgefragten Daten dem lokalen Eintrag über die Tabellenansicht hinzugefügt werden, wobei beim jeweiligen Datenfeld lediglich ein kleiner Button betätigt werden muss.
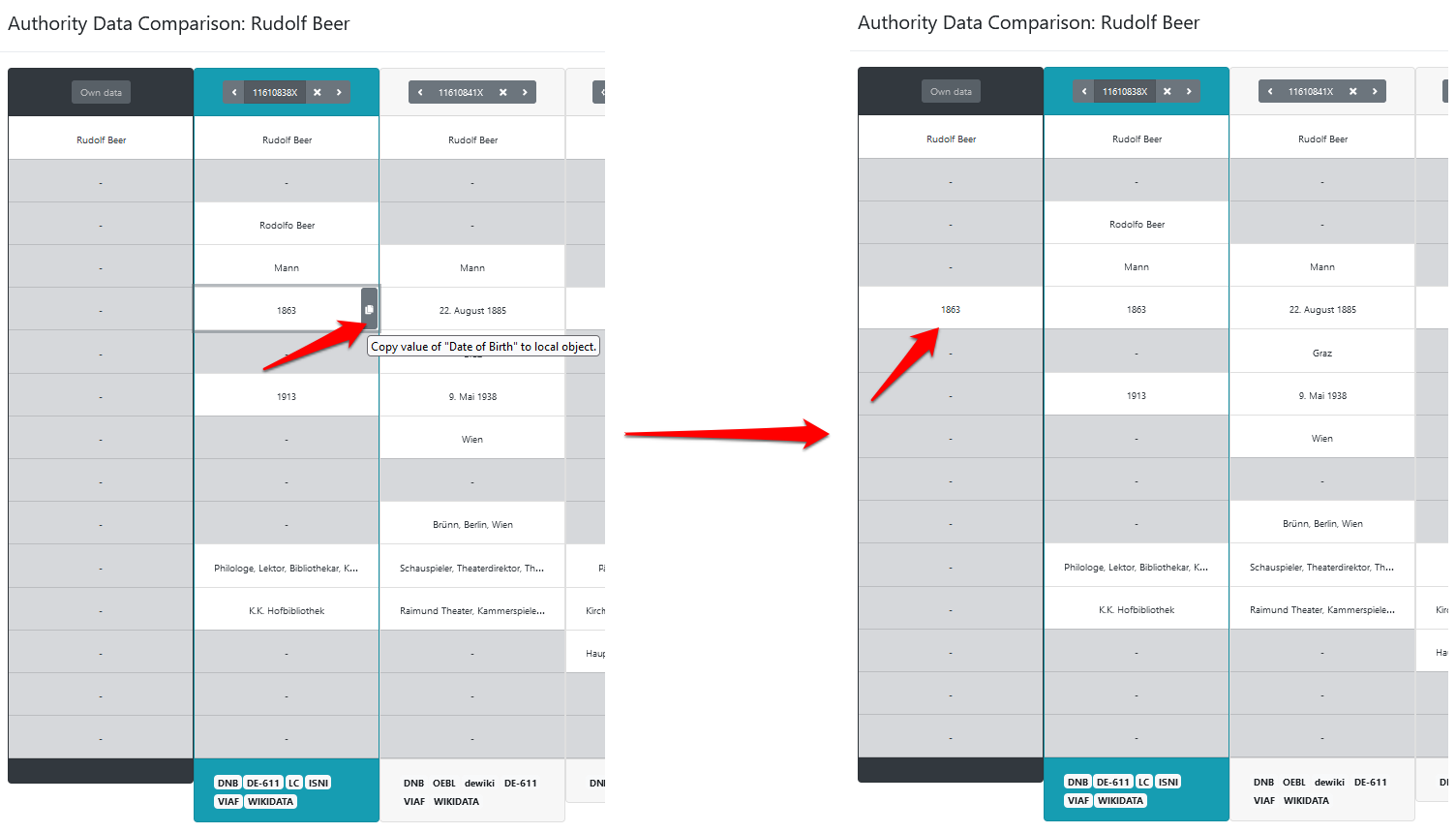
Das Hinzufügen von Daten zum lokalen Datensatz - In der Tabellenansicht selbst können diese Informationen nicht wieder entfernt werden, das ist nur über den Button zum Editieren der Entitätsdaten (Stift- und Papiersymbol, siehe Abb. 5) möglich
4. Export der Daten
- Nachdem wir alle Personeneinträge bearbeitet haben, wollen wir die Daten exportieren, um im Zuge unserer Transition die Named-Entity-Einträge im
<standOff>der Briefe mit den GND- und GeoNames-Links anreichern zu können. Als Optionen stehen ein Merge mit einer bereits existierenden CSV-Datei (generisch oder im CMI-Format (Konvertierungstool)) oder ein einfacher Download als JSON-Datei zur Verfügung. Da wir über keine CSV-Datei verfügen, entscheiden wir uns für letztere Option. - Evaluation der Daten: In den exportierten JSON-Dateien sind folgende Informationen verzeichnet:
“id”: Dabei handelt es sich um die@xml:idder importierten Entitäten“status”: Der von uns der Entität zugewiesene Status, z. B. “safe”“name”: Der Name der importierten Entität, z. B. “Rudolf Beer”“identifier”: Hier werden die Identifier aller möglichen Matches ausgegeben, wobei das Key-Value-Paar“prefered”: “YES”den von uns ausgewählten Identifier ausweist.
{
"person": [
{
"id": "P.HJ",
"status": "safe",
"name": "Henry d´Arbois de Jubainville",
"identifier": [
{
"preferred": "YES",
"#text": "https://d-nb.info/gnd/116317353"
}
]
},
{
"id": "P.OB",
"status": "safe",
"name": "Friedrich August Otto Benndorf",
"identifier": [
{
"preferred": "YES",
"#text": "https://d-nb.info/gnd/116121157"
}
]
},
{
"id": "P.HS",
"status": "safe",
"name": "Hugo Schuchardt",
"identifier": [
{
"preferred": "YES",
"#text": "https://d-nb.info/gnd/118611046"
}
]
},
{
"id": "P.FM",
"status": "safe",
"name": "Franz von Miklosich",
"identifier": [
{
"preferred": "YES",
"#text": "https://d-nb.info/gnd/119065932"
}
]
},
{
"id": "P.GK",
"status": "safe",
"name": "Gregor Krek",
"identifier": [
{
"preferred": "YES",
"#text": "https://d-nb.info/gnd/118945548"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/11893645X"
}
]
},
{
"id": "P.GM",
"status": "safe",
"name": "Gustav Meyer",
"identifier": [
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/118582046"
},
{
"preferred": "YES",
"#text": "https://d-nb.info/gnd/117558869"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/117558885"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/11700877X"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/117570125"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/144014912"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/143518216"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/130304204"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/139747036"
}
]
},
{
"id": "P.TB",
"status": "unavailable",
"name": "Theodor von Busse"
},
{
"id": "P.FS",
"status": "unavailable",
"name": "Friedrich Schmidt",
"identifier": [
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/117504300"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/120078260"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/117504750"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/117511161"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/130455296"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/119259184"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/134663837"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/1045255564"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/1051792304"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/133868303"
}
]
},
{
"id": "P.CU",
"status": "safe",
"name": "Christian Cornelius Uhlenbeck",
"identifier": [
{
"preferred": "YES",
"#text": "https://d-nb.info/gnd/117268739"
}
]
},
{
"id": "P.ED",
"status": "safe",
"name": "Edward Spencer Dodgson",
"identifier": [
{
"preferred": "YES",
"#text": "https://d-nb.info/gnd/117646075"
}
]
},
{
"id": "P.RB",
"status": "safe",
"name": "Rudolf Beer",
"identifier": [
{
"preferred": "YES",
"#text": "https://d-nb.info/gnd/11610838X"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/11610841X"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/101158056X"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/1230818847"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/1034697110"
},
{
"preferred": "NO",
"#text": "https://d-nb.info/gnd/1073306224"
}
]
}
]
}
Kontakt
Weblinks: https://basicdemo.saw-leipzig.de/
GitHub: https://github.com/saw-leipzig/basic.app
| Uwe Kretschmer | kretschmer@saw-leipzig.de |
Ressourcen
Dokumentation
- Derzeit ist keine Dokumentation verfügbar (Stand: September 2023)
Tutorials
- Derzeit sind keine Tutorials verfügbar (Stand: September 2023)
Projekte, die dieses Tool genutzt haben
- Derzeit sind keine Projekte bekannt, die ba[sic?] genutzt haben (Stand: September 2023)
Literatur
- Derzeit ist noch keine Literatur zu ba[sic?] verfügbar (Stand: September 2023)
Factsheet
| System | |
| Scope des Tools | Normdatenanreicherung |
| Softwareumgebung/Softwaretyp (Remotesystem im Browser / Lokaler Client) |
Browser-Anwendung |
| Unterstützte Plattformen | Linux, Windows & Mac |
| Geräte | Desktop, Laptop |
| Einbindung anderer Systeme (Interoperabilität) | ✅ (GND (Personen und Organisationen), Geonames.org (Orte)) |
| Accountsystem | ❌ (keine Anmeldung erforderlich) |
| Kostenmodell (Kostenübersicht / Open Source) |
kostenlos, Open Source |
| Anforderungen & Methoden | |
| Erforderte Code Literacy | keine |
| Interface-Sprachen (ISO 639-1) | en |
| Unterstützte Zeichenkodierung | keine Information auffindbar (vermutlich UTF-8) |
| Inkludierte Datenkonvertierung (Im Pre-Processing mögliche Anpassung der Daten an für die Software erforderliches Format) |
❌ |
| Abhängigkeit von anderer Software (Falls ja, wird diese Software automatisch mitinstalliert?) |
❌ |
| Erforderliche Plug-Ins (bei web-basierten Anwendungen) |
❌ |
| Dokumentation & Support | |
| Wartung und ständige Erweiterung | ❌ (letzter GitHub-Commit vor 2 Jahren (Stand: September 2023) |
| Einbindung der Community | ❌ |
| Dokumentation | ❌ |
| Dokumentationssprache | [nicht anwendbar] |
| Dokumentationsformat | [nicht anwendbar] |
| Dokumentationsabschnitte | [nicht anwendbar] |
| Verfügbarkeit von Tutorials | ✅Kurzer Quickstartguide auf der Startseite, weiterführende Hinweise werden im Zuge der Nutzung der Anwendung gegeben |
| Aktiver Support/Community (Forum, Slack, Issue Tracker etc.) |
❌ |
| Nutzbarkeit & Nachhaltigkeit | |
| Installationsablauf | [nicht anwendbar] |
| Test (Gibt es ein Test Suite, um zu überprüfen, ob die Installation erfolgreich war?) |
[nicht anwendbar] |
| Lizenz, unter der das Tool veröffentlicht wurde | MIT-Lizenz |
| Registrierung in einem Repository | ✅ (GitHub) |
| Möglichkeit zur Software-Entwicklung beizutragen | ❌ |
| Benutzerinteraktion & Benutzeroberfläche | |
| Benutzerprofil (erwartete Nutzer:innen) |
u. a. Ersteller:innen digitaler Editionen |
| Benutzerinteraktion (erwartete Nutzung) |
Hochladen von Dateien, Anreicherung der Dateien mit Normdaten, Export von Dateien |
| Benutzeroberfläche | browserbasiertes GUI |
| Visualisierungen (Analyse-, Input-, Outputkonfigurationen) |
✅(Tabellarischer Vergleich der gefundenen Normdaten, farblich unterschiedliche Darstellung der Ergebnisse je nach zugewiesenem Status) |
| Benutzerverwaltung | |
| Personenverwaltung | ❌ |
| Interne Kommunikationsmöglichkeiten (z. B. Annotationsrichtlinen, Kommentarfunktionen, …) |
❌ |
| Daten- und Toolverwaltung | |
| Zentrale/dezentrale Verwaltungsmöglichkeit | ✅ Mehrere Datensätze parallel anlegbar |
| Versionskontrolle | ❌ Zeit- und Datumsangabe der letzten Änderung wird angezeigt, allerdings keine Möglichkeit des Rückgängigmachens und Wiederherstellens von Änderungen |
| Projektspezifische Einstellungen | ❌ |
| API | ❌ |
| Möglichkeit auf simultanes Arbeiten | ❌ |
| Datenupload | |
| Unterstützte Dateiformate | CSV (generisch oder durch CSV2CMI im CMI-Format), XML, JSON (Reupload von bereits als JSON einmal exportierten Datensätzen) |
| Informationen zur Datensicherheit | Für die hochgeladenen Daten wird der Local Storage des Browsers bzw. Geräts genutzt, die Daten werden nicht an Server übertragen |
| Zugänglichkeit von verschiedenen Standorten/Geräten | ❌ |
| Einschränkungen hinsichtlich der Datenmenge | keine Angabe |
| Verlustfreier Upload von bereits bearbeiteten Dokumenten | ✅ |
| Unterstützung von IIIF-Import | [nicht anwendbar] |
| Datenbearbeitung (Normalisierungstool) | |
| Komplexitätsgrad der Normalisierung (z. B. Verfügbarkeit von Buttons, Drag&Drop-Funktion, …) |
✅Auswahl der Matches und deren Status über Buttons und Reiter |
| Reconciliation-Möglichkeiten entsprechend bestimmten Standards für digitale Editionen | ✅ GND, GeoNames |
| Anpassungsmöglichkeit und Validierung entsprechend projektspezifischen Konventionen/Schemata | ❌ |
| Datenexport | |
| Unterstützte Dateiformate | JSON, CSV (generisch oder durch CSV2CMI im CMI-Format) |
| Datenverlust (nicht vollständiger Erhalt von Annotationen, die bereits vor Verwendung des Tools gemacht wurden) |
[nicht anwendbar] |
| Validierungsmöglichkeit für TEI-XML vor Export | [nicht anwendbar, da keine Möglichkeit eines (TEI-)XML-Exports] |
| Datenaufbewahrung nach Export | ❌ Datensätze bleiben allerdings im Local Storage des Browsers bzw. Geräts gespeichert |